Attention is All You Need

Introduction and Background
-
Previous works for language modeling and machine translation
- Recurrent neural networks (RNN)
- Long short-term memory (LSTM)
- Gated recurrent neural networks (GRN)
- Recurrent models
- Positions $\rightarrow$ Computation time
- Generates a sequence of hidden states $h_t$
- $h_t$=$f(h_{t-1}, x_t)$
- Precludes parallelization within training examples :(
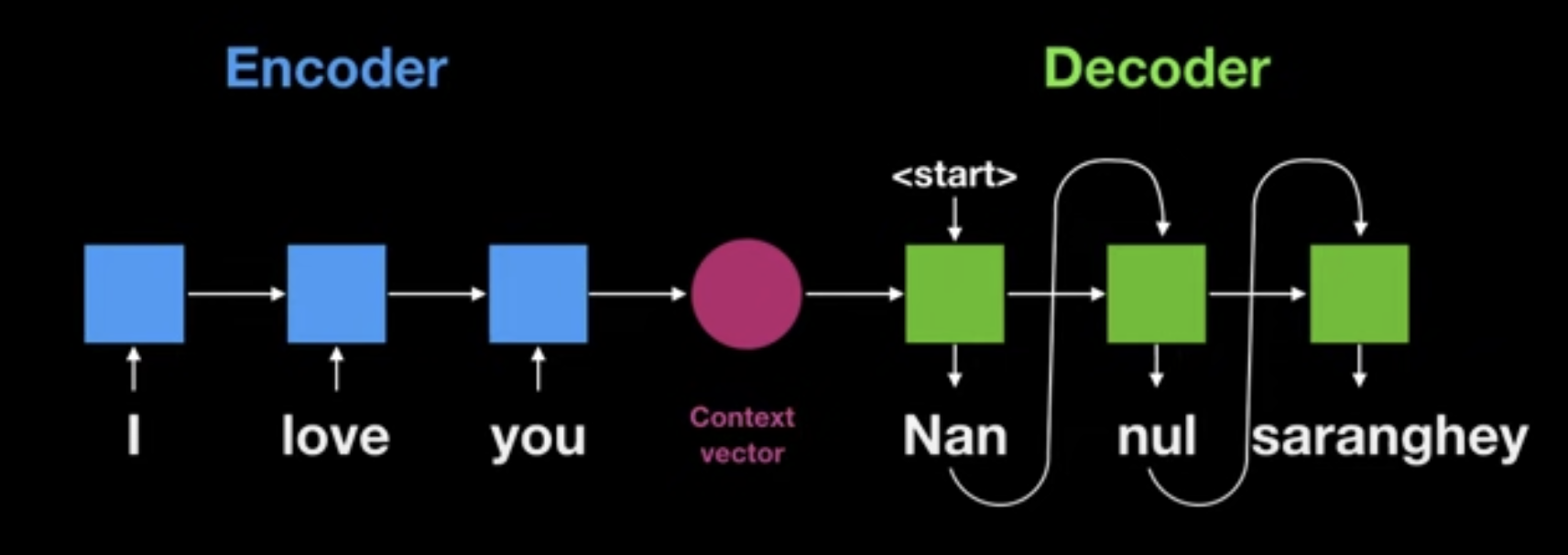
- Reducing sequential computation for sequential data!
-
CNN as building block
- Extended Neural GPU
- ByteNet
- ConvS2S
-
CNN as building block
- Attention model
- Allowing modeling of dependencies without regard to their distance in the input or output sequences
- Used in conjunction with a recurrent network
- Ref: Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. “Neural machine translation by jointly learning to align and translate.“ arXiv preprint arXiv:1409.0473 (2014).
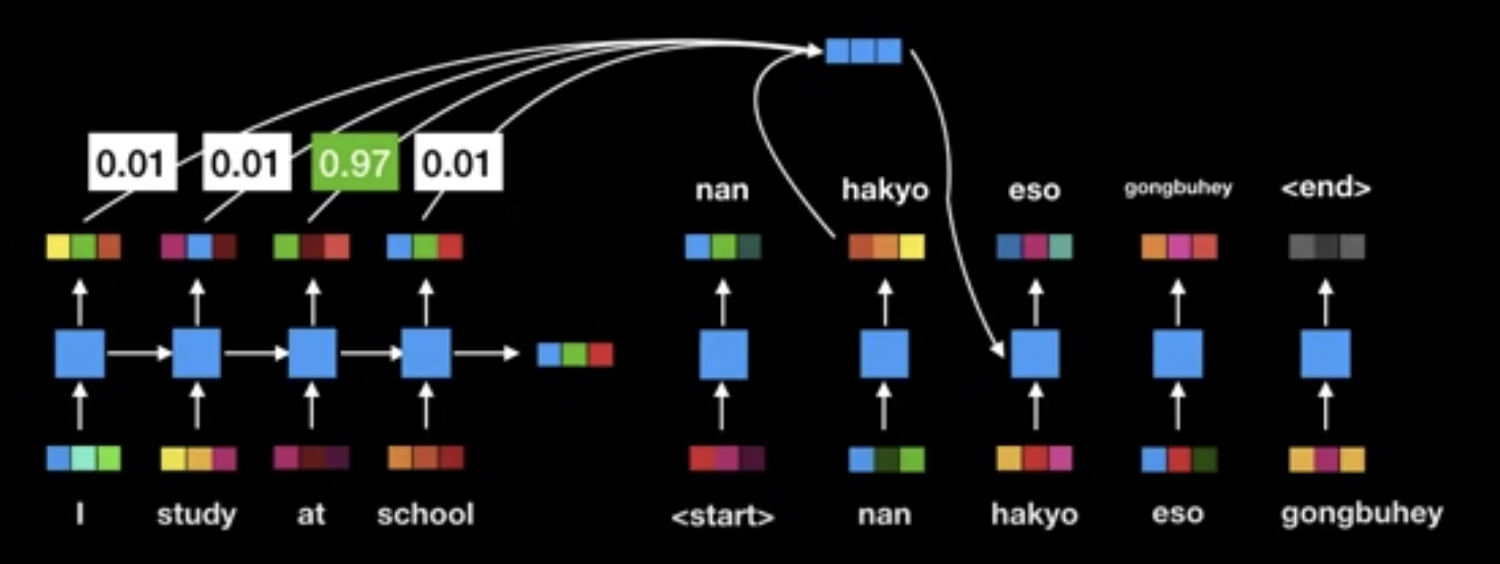
- Self attention
- $a.k.a.$ intra-attention
- Attention mechanism relating different positions of a single sequence
- In order to compute a representation of the sequence
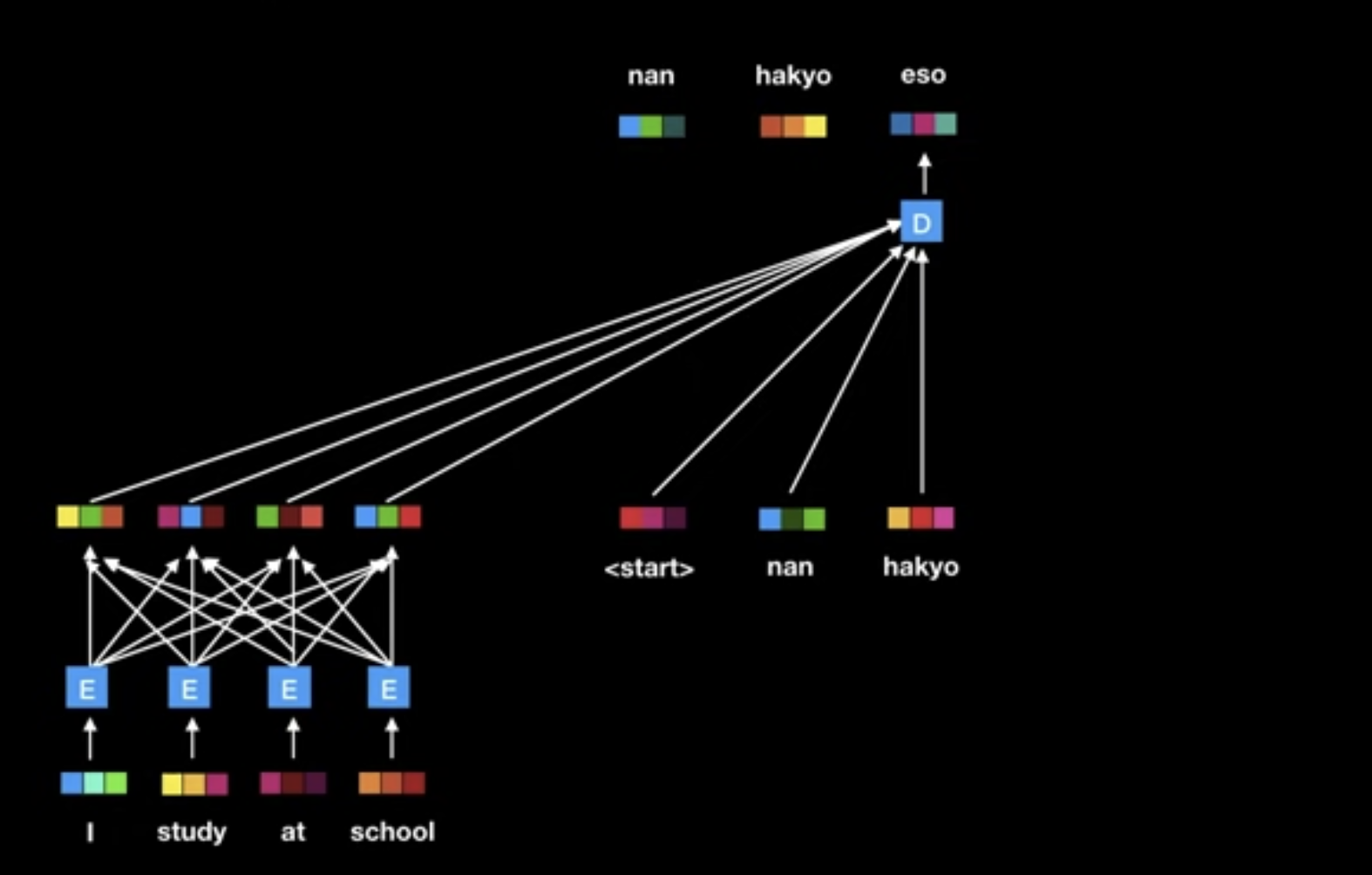
- Transformer
- Eschewing recurrence
- Relying entirely on an self-attention mechanism: No RNN or CNN
- Draw global dependencies between input and output
- SOTA translation quality after 12 hours with 8 P100 GPUs
- Highlight:
- RNN already had ability to predict “next word to come”
- if it is given “well-extracted summary of previous word sequence”
- So, our focus is how to “efficiently extract summary of previous word sequence”
- That’s what the Transformer and the self-attention is all about
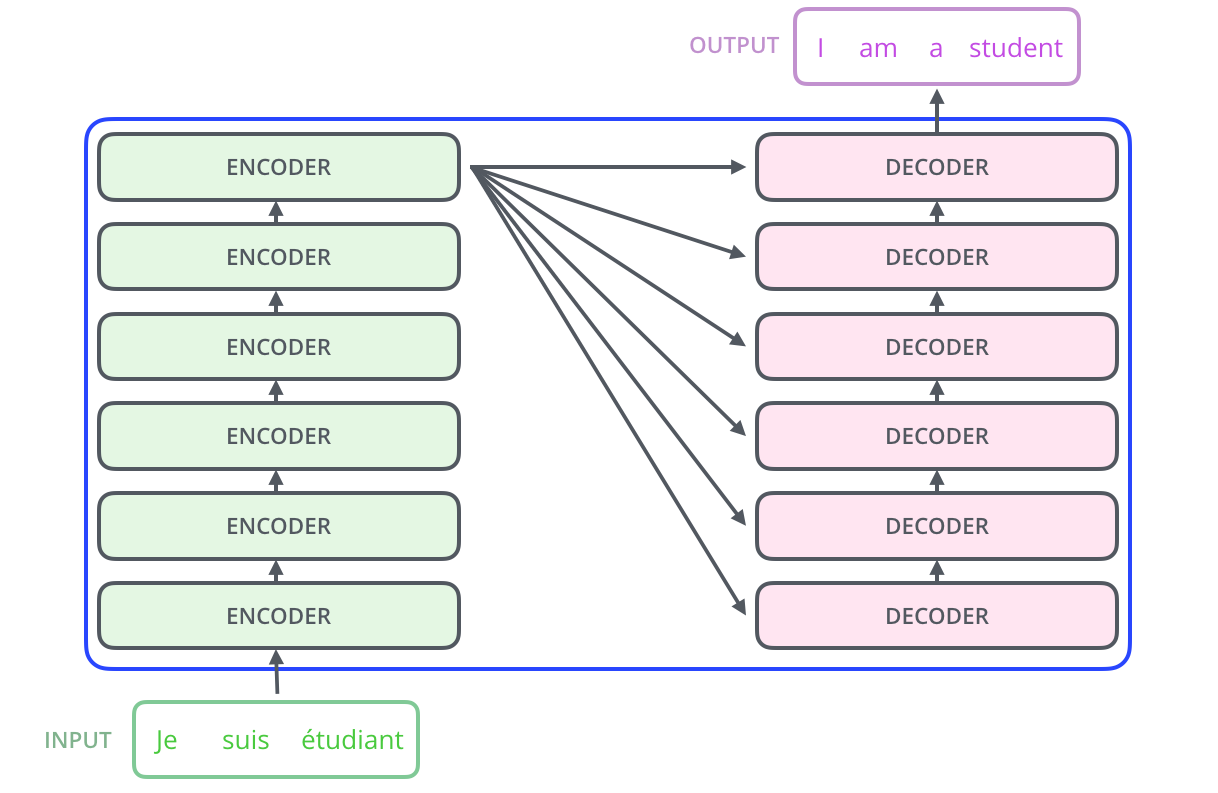
Model Architecture
- Encoder-Decoder structure
- Encoder:
- Maps an input seq of symbol representation $x = (x_1, x_2, … , x_n)$
- To a seq of continuous representation $z = (z_1, z_2, … , z_n)$
- Decoder:
- Given $z = (z_1, z_2, … , z_n)$, generates output seq $y = (y_1, y_2, … , y_m)$
- Auto-regressive
- Consume previously generated symbols as additional input
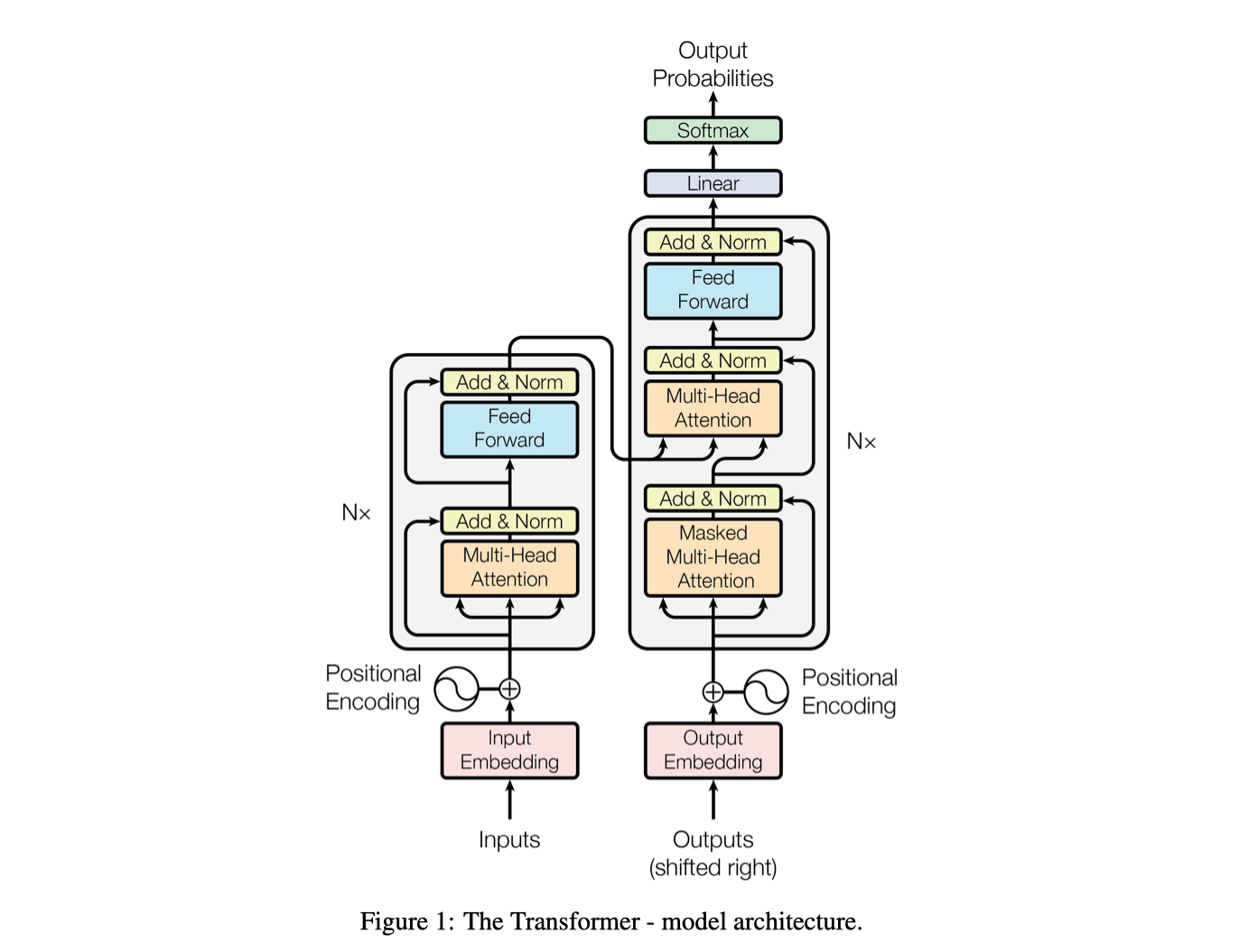
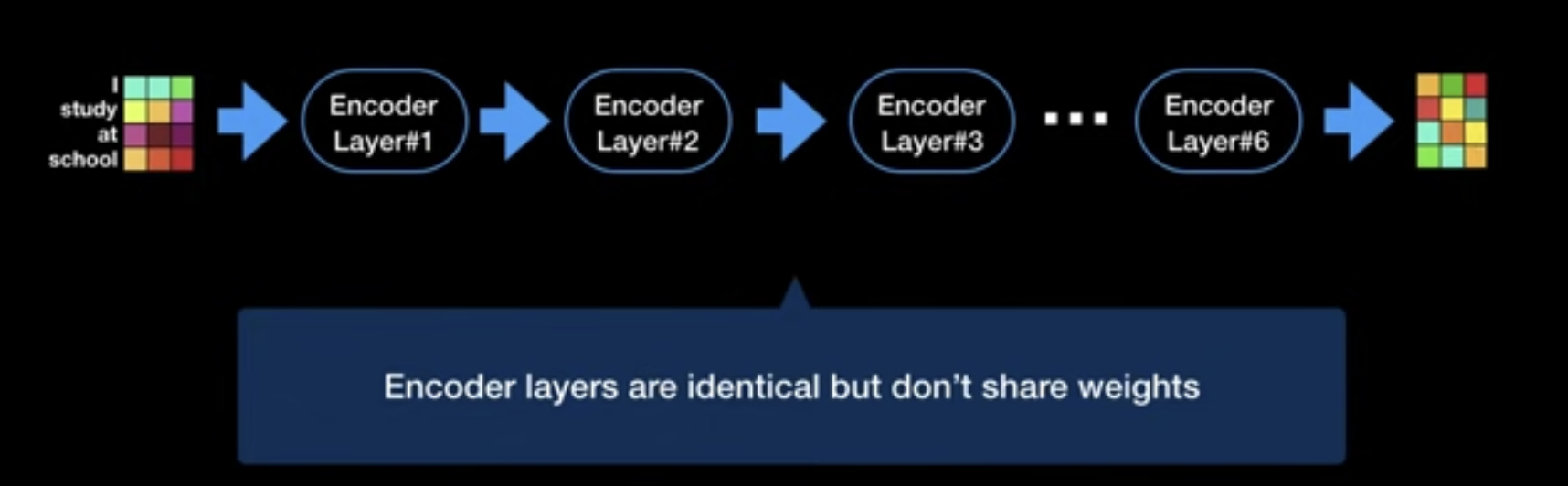
Encoder Stack
- Stack of N=6 identical layers
- Each layer with two sub-layers
-
Multi-head self-attention mechanism
- With residual connection (
Add) - Followed by layer normalization (
Norm)
- With residual connection (
- Position-wise fully connected feed-forward network
- With residual connection (
Add) - Followed by layer normalization (
Norm)
- With residual connection (
-
Multi-head self-attention mechanism
- Output dimension of sub-layers and embedding layers $d_{model}$ are all the same
- To enable residual connection
- $d_{model}$ = 512
Decoder Stack
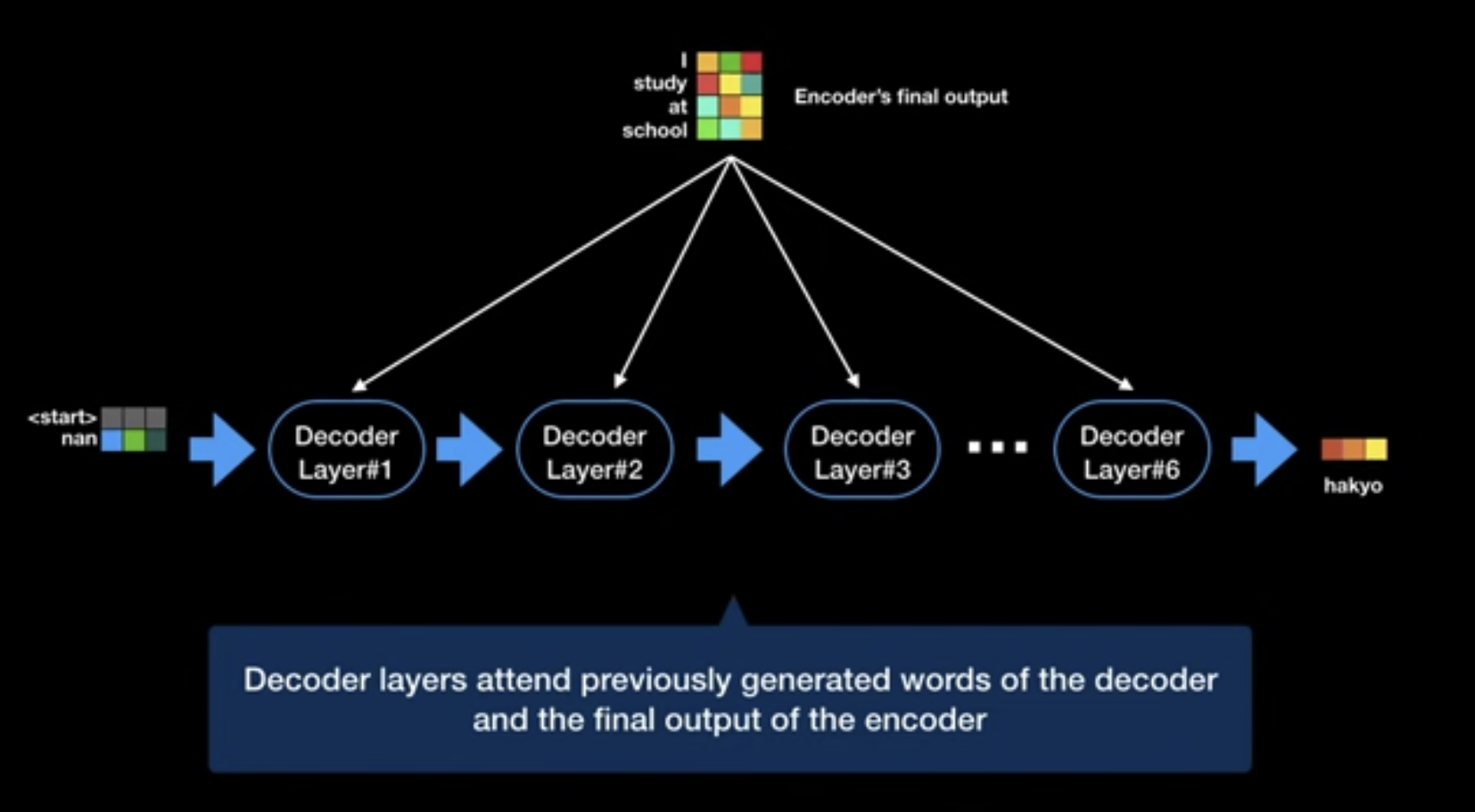
- Stack of N=6 identical layers
- Each layer with three sub-layers
-
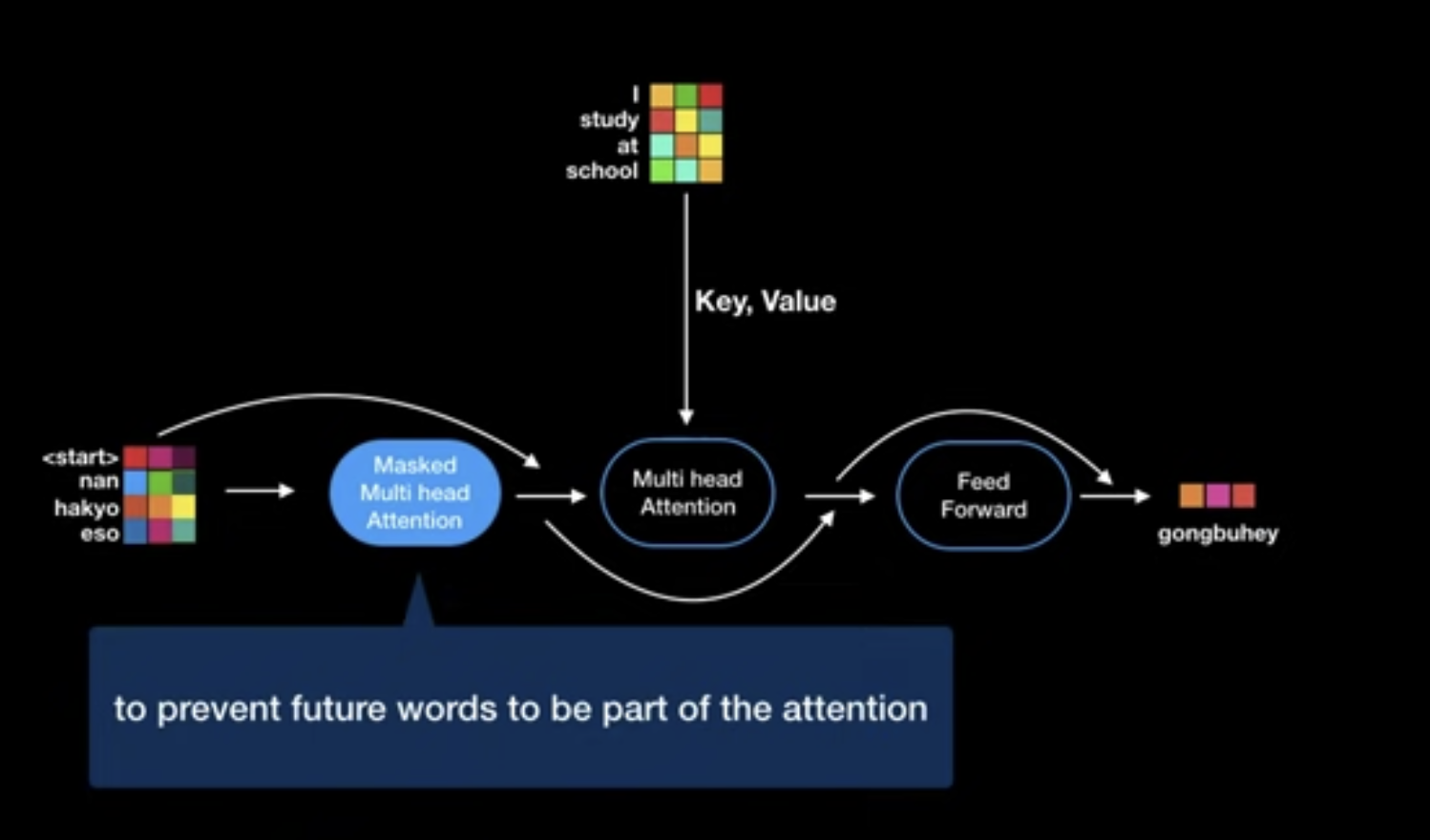
Masked(!) Multi-head self-attention mechanism
- With residual connection (
Add) - Followed by layer normalization (
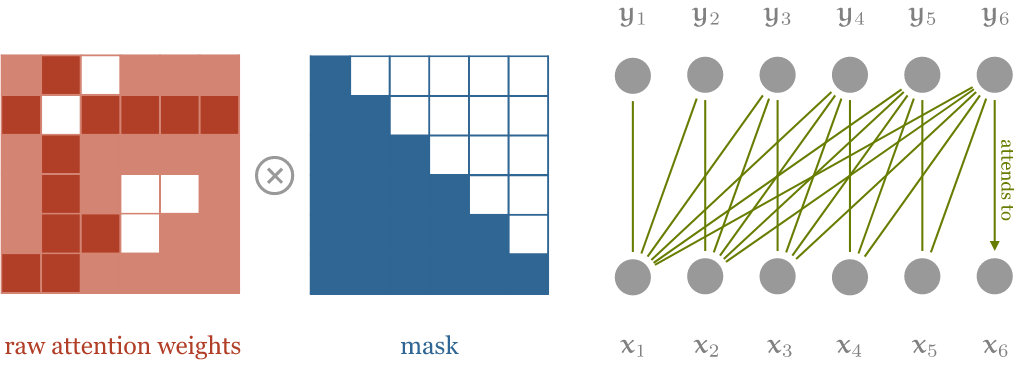
Norm) - Masking
- Prevent positions from attending to subsequent positions
- With residual connection (
-
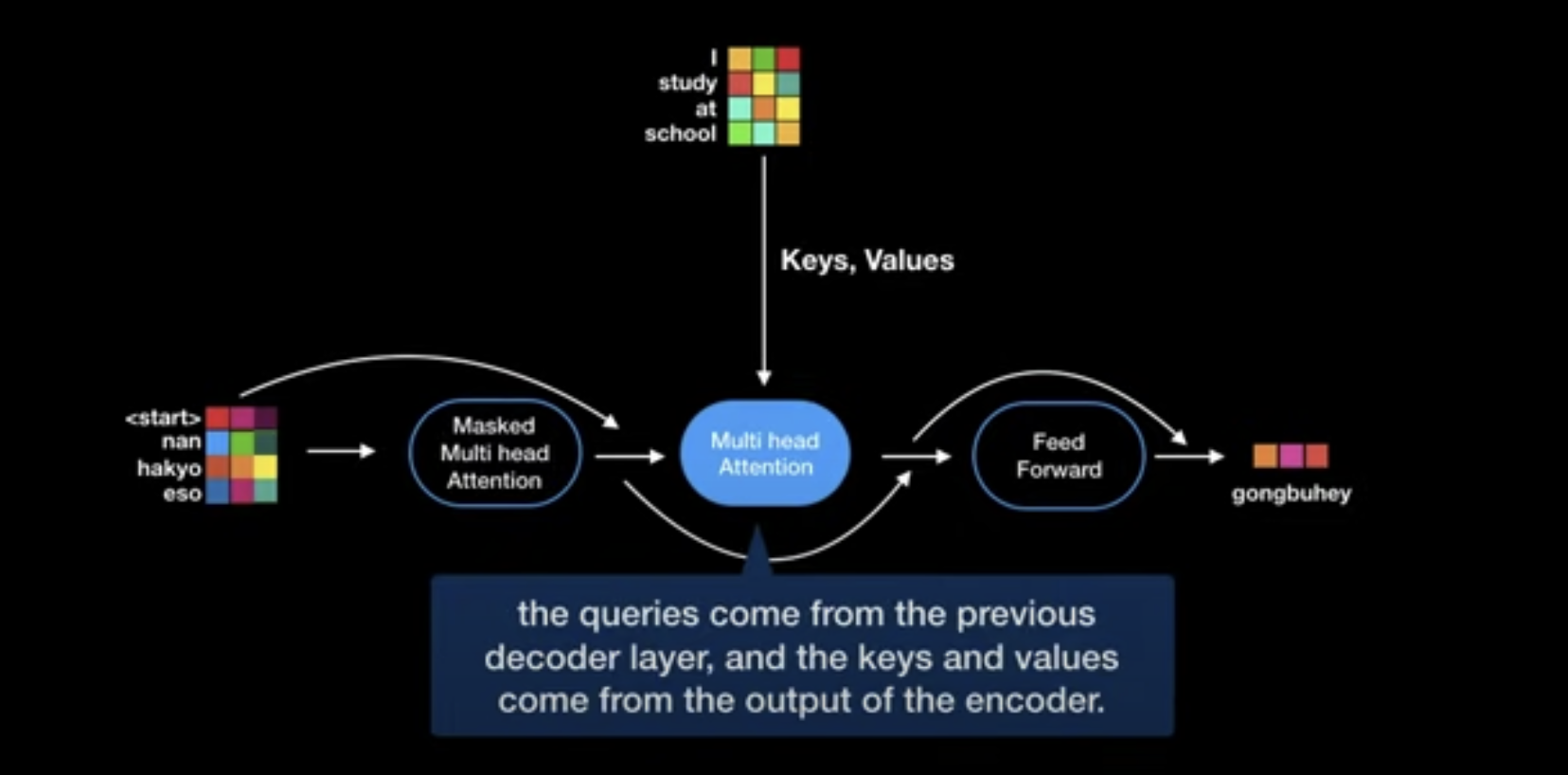
Multi-head encoder-decoder attention over the output of the encoder stack
- Input
- $Q$ projected from of previous multi-head self-attention sub-layer
- $K$ and $V$ projected from output of encoder stack
- With residual connection (
Add) - Followed by layer normalization (
Norm) - Masking
- Prevent positions from attending to subsequent positions
- The predictions for position $i$ can depend only on the know outputs at positions less than $i$
- Input
- Position-wise fully connected feed-forward network
- With residual connection (
Add) - Followed by layer normalization (
Norm)
- With residual connection (
- Output dimension of sub-layers and embedding layers $d_{model}$ are all the same
- To enable residual connection
- $d_{model}$ = 512
-
Masked(!) Multi-head self-attention mechanism
Attention
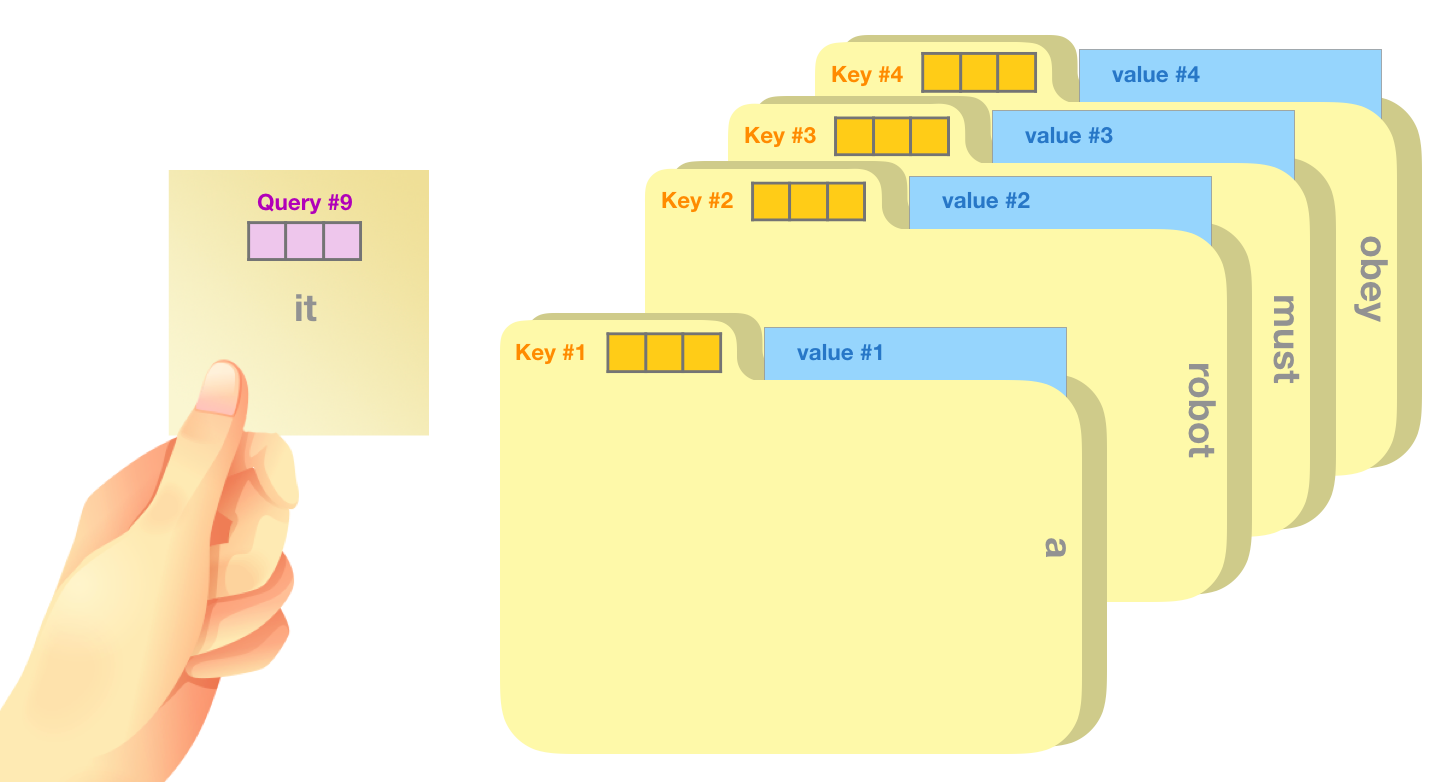
- Attention function
- Mapping a query and a set of key-value pairs to an output
- Output = Weighted sum of the values
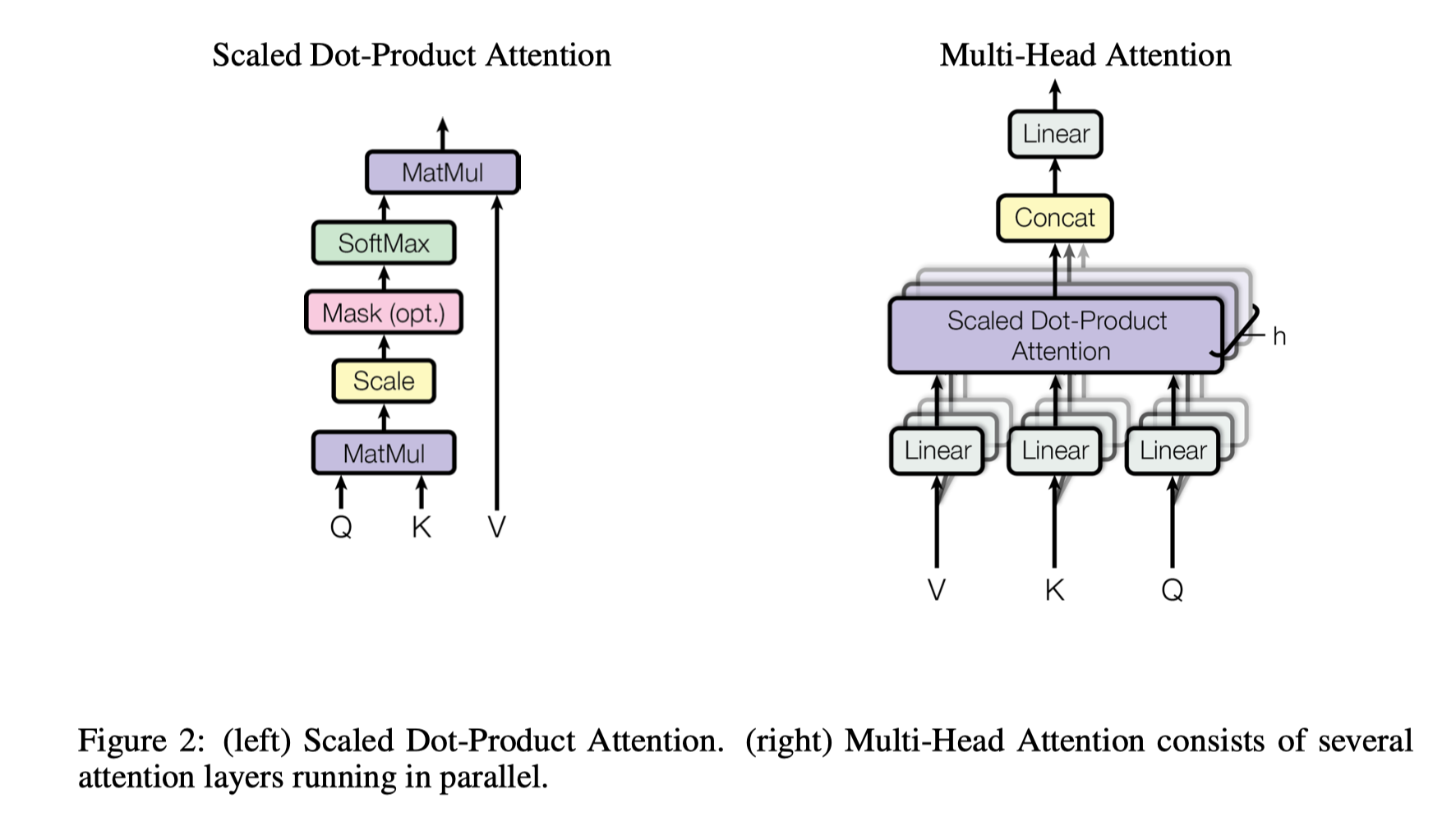
Scaled Dot-Product Attention
-
Input: queries and keys of dimensions $d_k$ and values of dimensions $d_v$
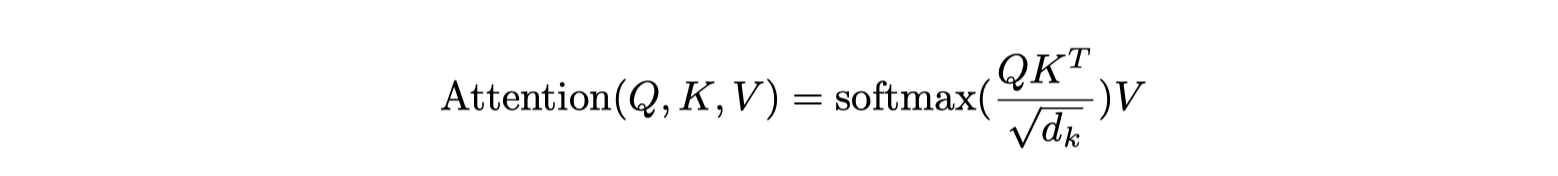
-
Scaling factor $1/\sqrt{d_k}$:
- The dot product may grow too large for large dimension $d_k$
- So the softmax function to be too small
- The scaling factor counteract this effect
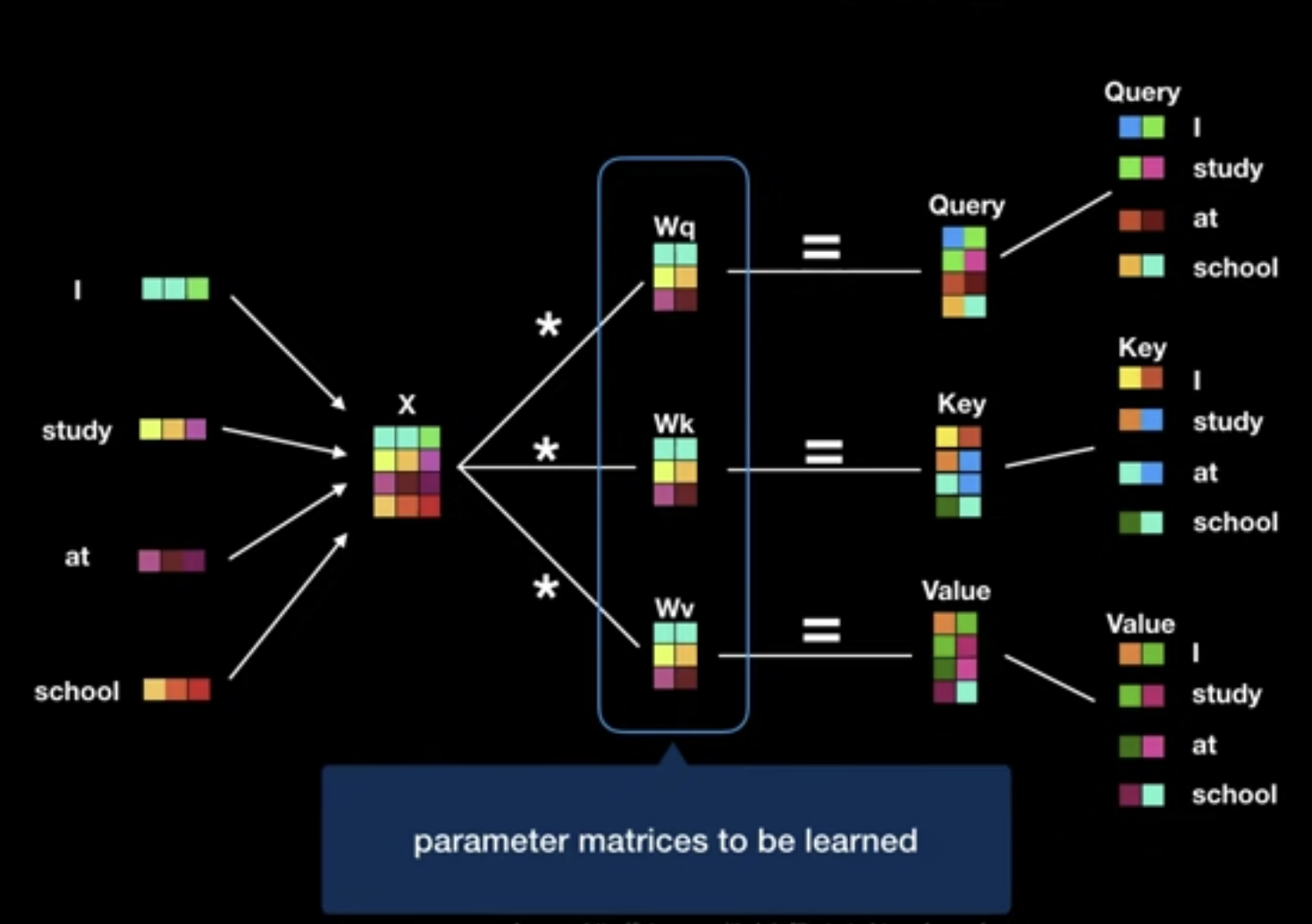

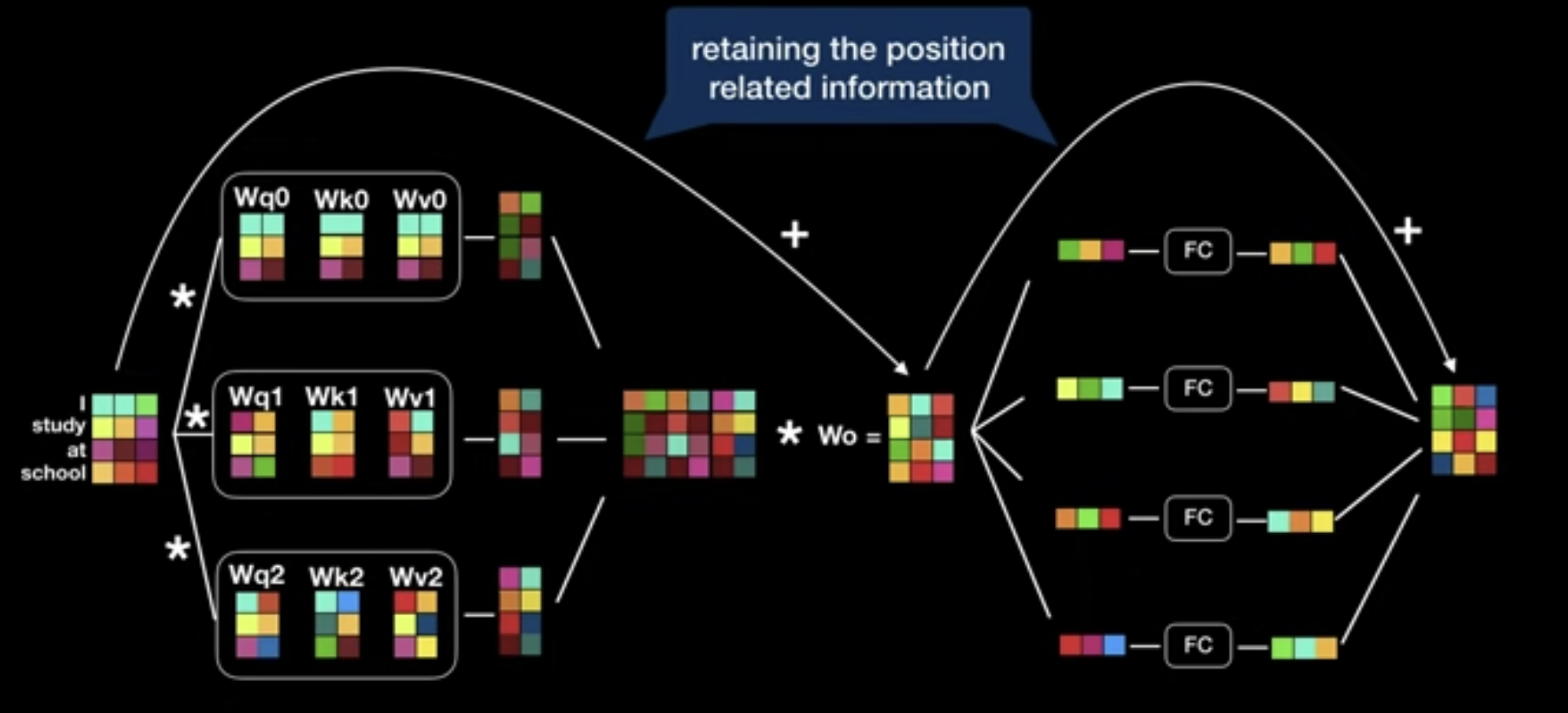
Multi-Head Attention
- To linearly project the Q, K, V $h$ times with different, learned linear projections to $d_k$, $d_k$ and $d_v$ dimensions
- Then, perform the attention function in parallel
- Yielding $d_v$ dimensional output values
- Concatenated to $h\times d_v$ dimensional vectors
- Once again linearly projected resulting in the final values

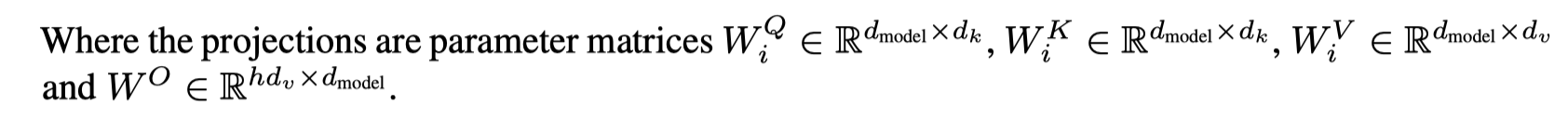
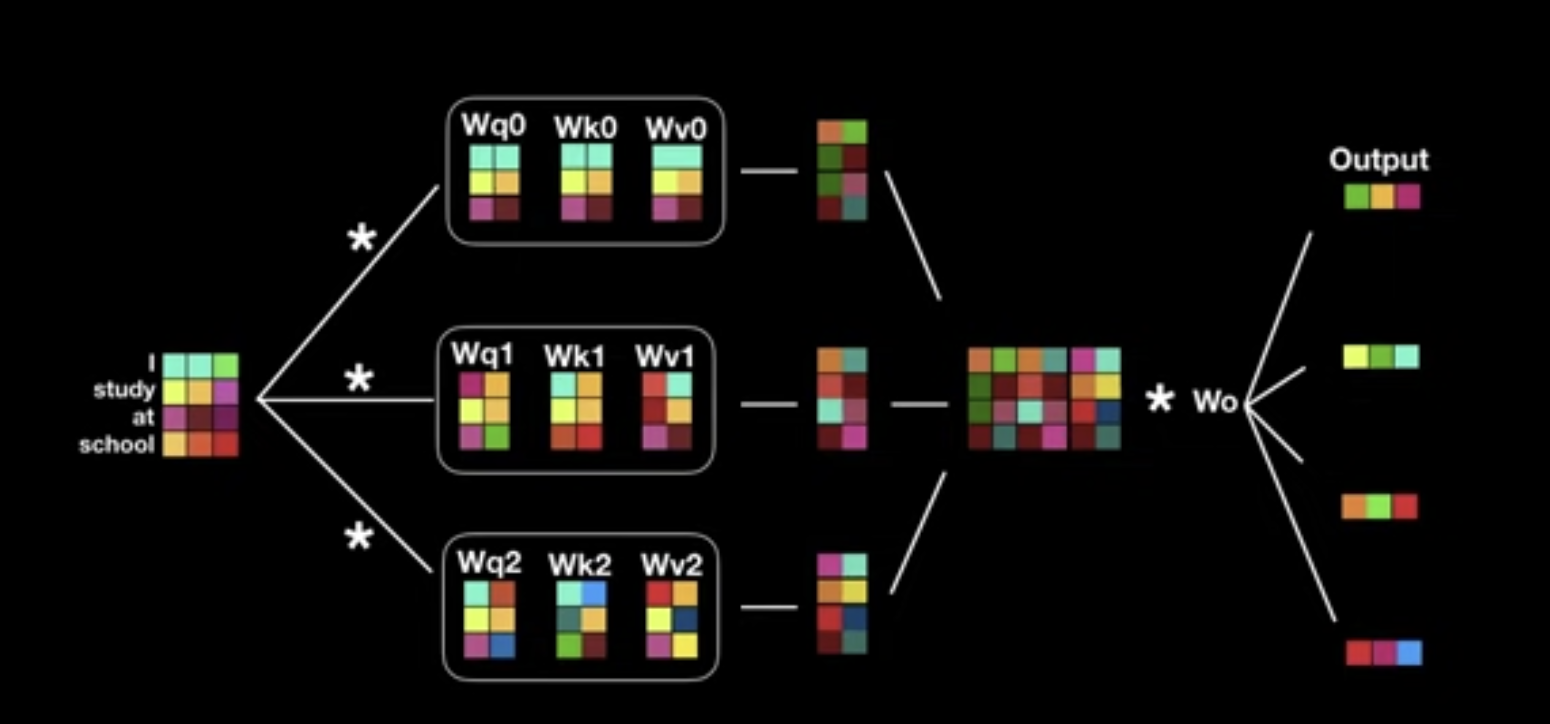
- Benefit?:
- Jointly attend to information from different representation subspaces at different positions
Applications of Attention in our Model
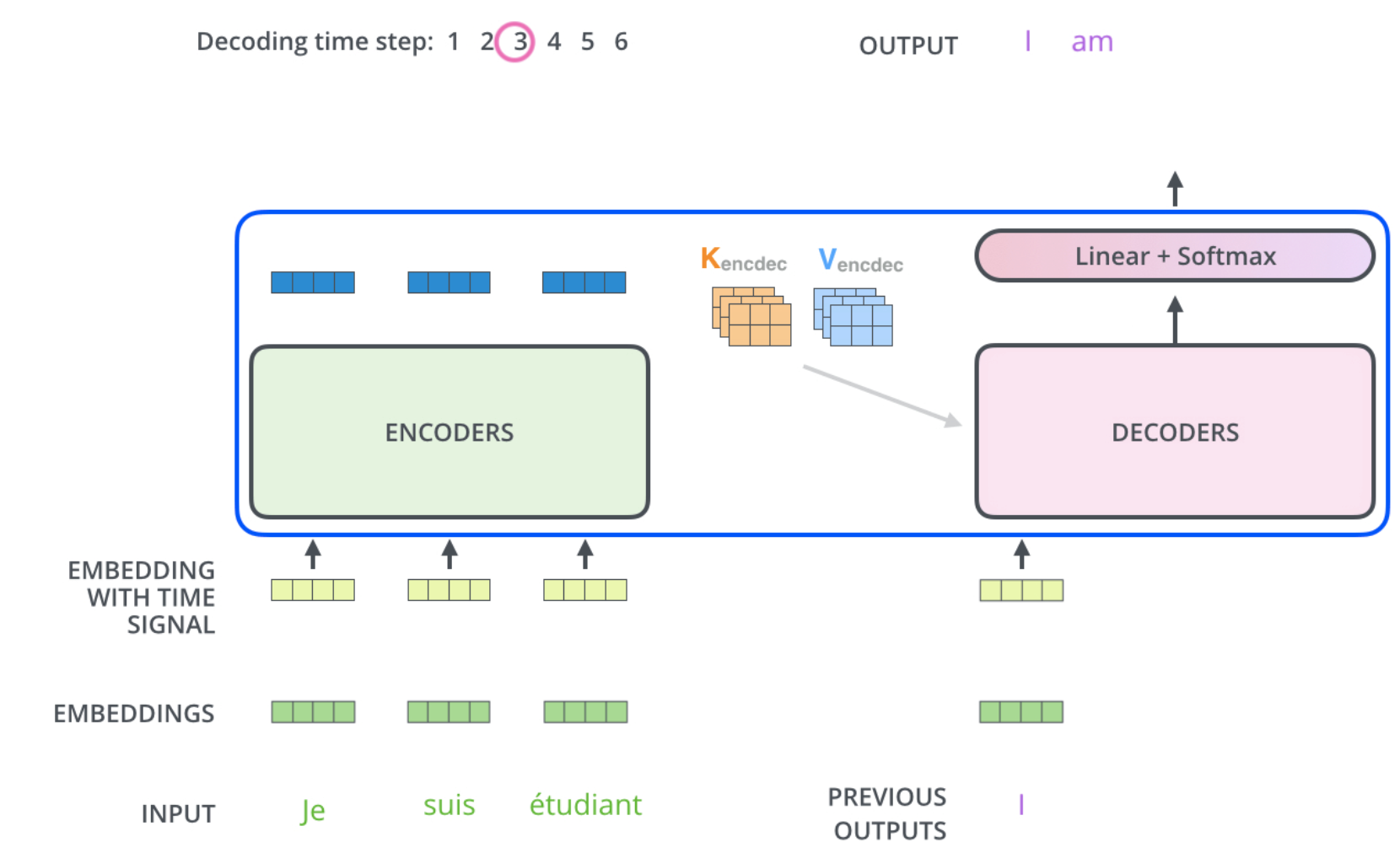
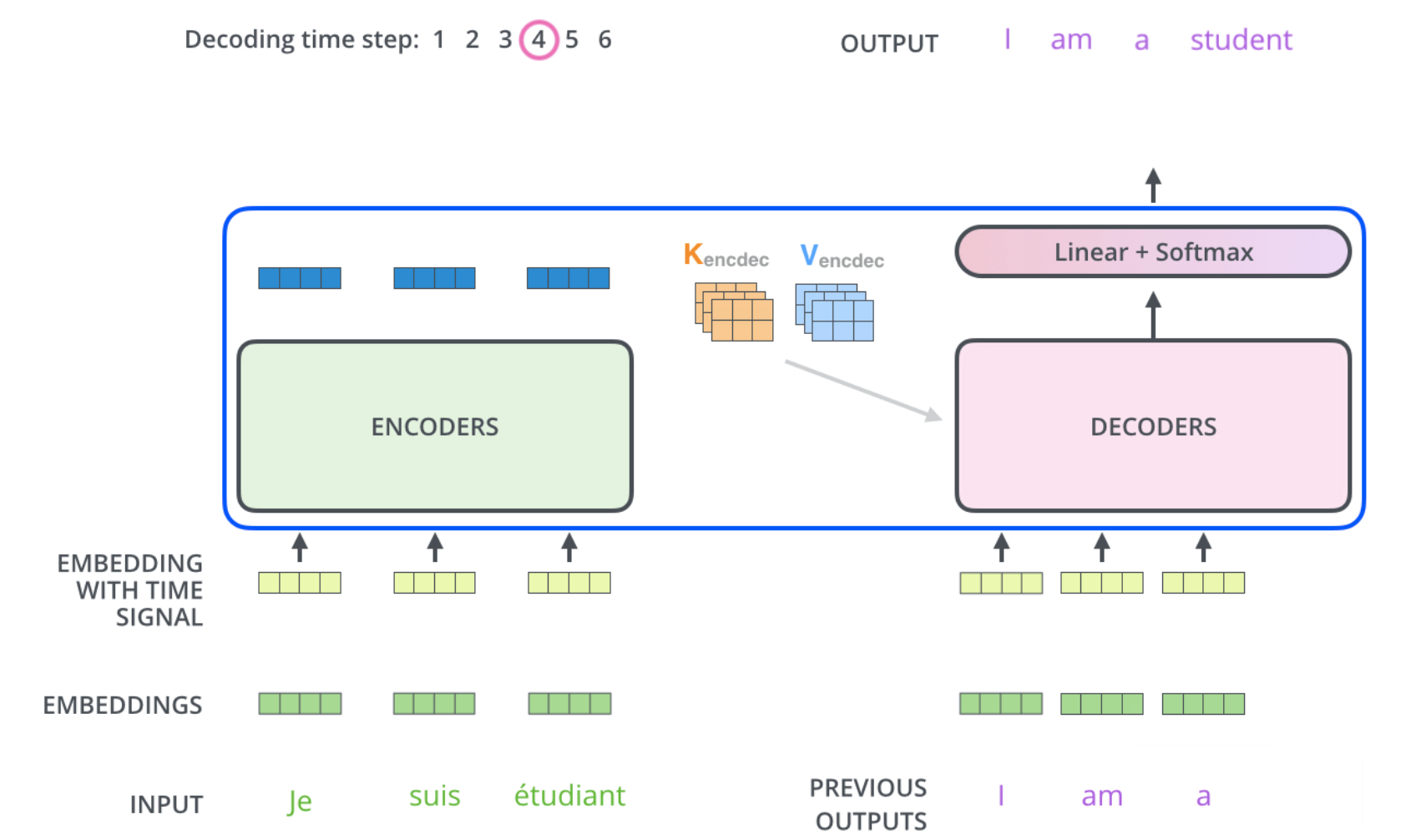
- Encoder-decoder attention layers
- The queries ($Q$) come from the previous decoder layer
- The memory keys ($K$) and values ($V$) come from the output of the encoder.
- Mimics encoder-decoder attention mechanisms in Seq-to-Seq models such as
- Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144, 2016.
- Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. CoRR, abs/1409.0473, 2014.
- Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N. Dauphin. Convolutional sequence to sequence learning. arXiv preprint arXiv:1705.03122v2, 2017.
- Self-attention layers
- Encoder:
- Keys ($K$), values ($V$) and queries ($Q$) come from the output of the previous layer in the encoder.
- Each position can attend to all positions
- Decoder:
- Keys ($K$), values ($V$) and queries ($Q$) come from the output of the previous layer in the decoder.
- Each position can attend to all positions up to and including that position $\rightarrow$ Need Mask!
- Encoder:
Position-wise Feed-Forward Networks
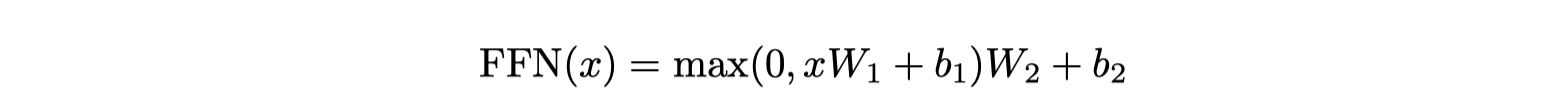
- Input/Output: $d_{model}$ = 512
- Inner-layer: $d_{ff}$ = 2048
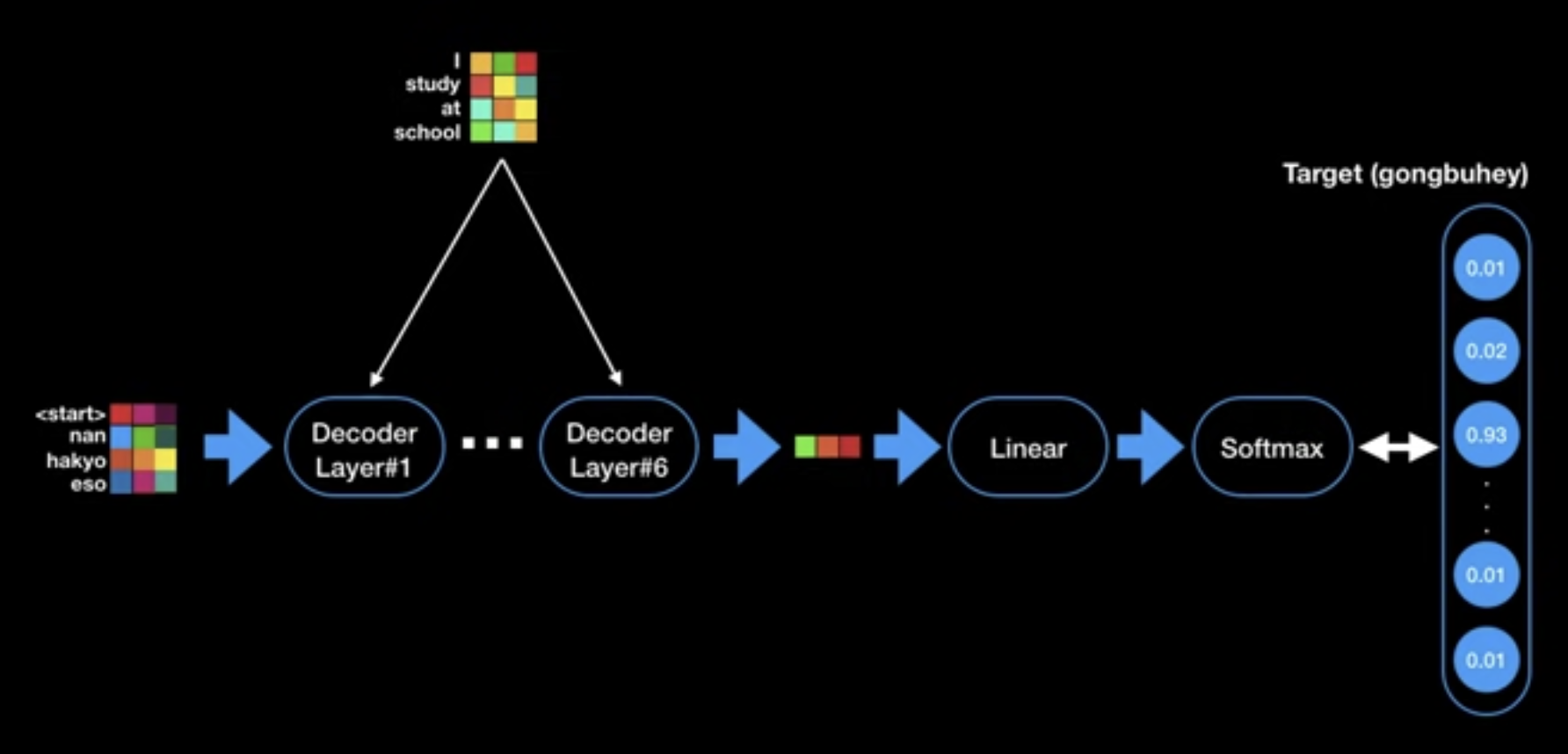
Embeddings and Softmax
- Used learned embeddings to convert the input tokens to output tokens with $d_{model}$ dimension
- Used learned linear transformation and softmax function
- to convert the decoder output to predicted next-token probabilities
- Shared weight matrices between encoder and decoder
Positional Encoding
- Must inject some information about
- the relative or
- absolute position of the tokens in the sequence
- Sine and cosine functions of different frequencies
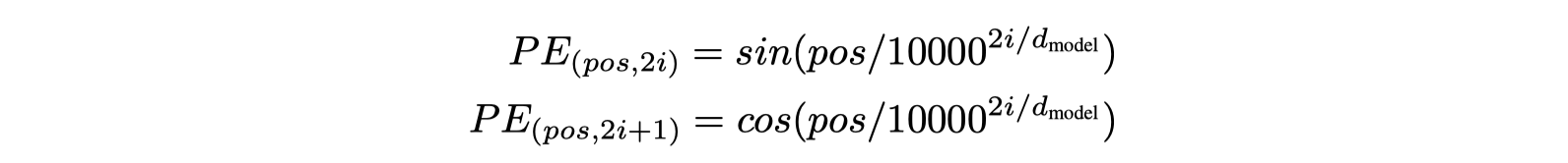
Why Self-Attention
- Better complexity
- Better parallelism
- Better path length between long-range dependencies in the network
- More interpretable models
- Different heads for different tasks

Training
- Dataset:
- WMT2014 English-German dataset
- 4.5 million sentence pairs
- Encoded using byte-pair encoding
- Source target vocabulary ~ 37000 tokens
- WMT2017 English-French dataset
- 36M sentences
- Split tokens into 32000 word-piece vocabulary
- WMT2014 English-German dataset
- Batch:
- a set of sentence pairs containing ~25000 source tokens and 25000 target tokens
- Hardware:
- 8 P100 GPUs
- Base model
- Each training step ~ 0.4 second
- 100,000 steps ~ 12 hours
- Big model
- ~ 1.0 seconds per step
- 300,000 steps ~ 3.5 days
- Optimizer
- Adam optimizer
- Warmup_steps = 4000
- Regularization
- Residual dropout
- Label smoothing
Results
- Machine translation
- WMT 2014 English-to-German translation task:
- 28.4 BLEU = 2.0 BLEU + SOTA
- WMT 2014 English-to-French translation task
- 41.0 BLEU = Outperforming all SOTA, 1/4 training cost
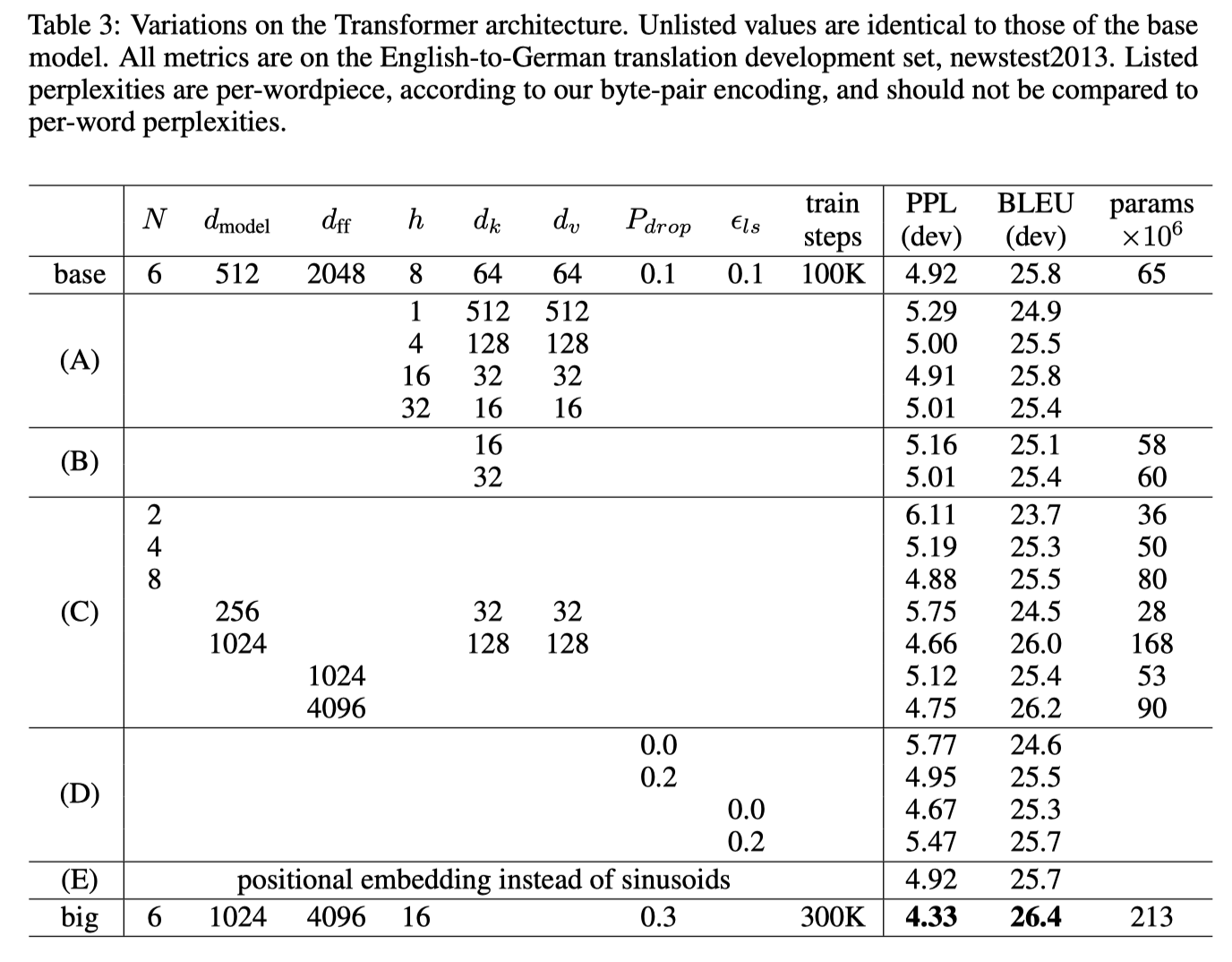
- WMT 2014 English-to-German translation task:
- Model variation
Reference
- Vaswani, Ashish, et al. “Attention is all you need.“ Advances in neural information processing systems 30 (2017).
- Github repository by the authors
- The Illustrated Transformer by Jay Alammar
- TRANSFORMERS FROM SCRATCH by Peter Bloem
- 트랜스포머 (어텐션 이즈 올 유 니드) by Minseok Heo
- GPT3 Architecture
- [[ Efficient Estimation of Word Representations in Vector Space ]]