Towards Automatic and Adaptive Optimizations of MPI Collective Operations
by Jelena Pjesivac-Grbovic
Abstract
Message passing interface (MPI) and collective operations (CO)
- CO: a subset of MPI standard that deals with processes …
- synchronization,
- data exchange and
- computation among a group of processes.
- CO can be a performance bottleneck
- CO parameters:
- input parameters (e.g., communicator and message size);
- system characteristics (e.g., interconnect type);
- the application computation and communication pattern;
- internal algorithm parameters (e.g., internal segment size) (referred as “method”)
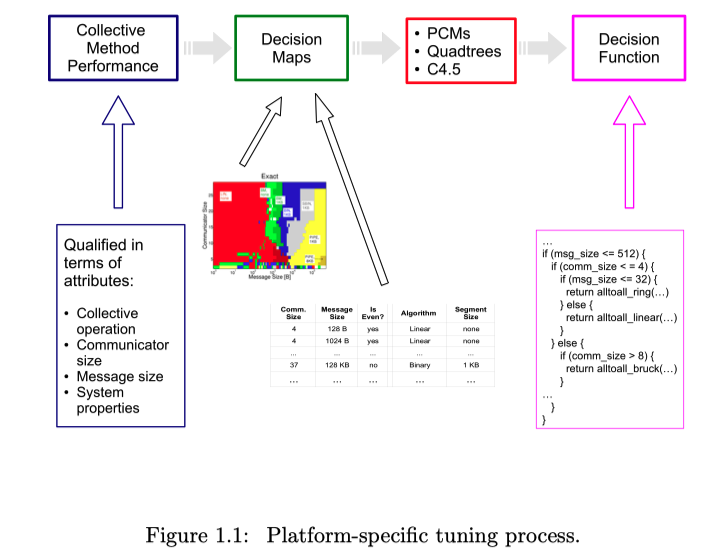
How to performance improvement of MPI collective operations
- In our framework, during a collective call, a system-specific decision function is invoked to select the most appropriate method for the particular collective instance.
- This dissertation focuses on automatic techniques for system-specific decision function generation.
- Our approach takes the following steps:
- we collect method performance information on the system of interest;
- we analyze this information using
- parallel communication models,
- graphical encoding methods, and
- decision trees;
- based on the previous step, we automatically generate the system-specific decision function to be used at run-time. In situation when a detailed performance measurement is not feasible, method performance models can be used to supplement the measured method performance information.
Ch.1 Introduction
Limits of single processor systems
$\rightarrow$ Parallel computing
- High-performance computing: TOP500 project
Difficulty of parallel software programming
- Level of parallelism
- Instruction-level
- Thread-level
- Process-level
Programmer’s view of system memory
- Shared memory
- Every process is able to access to remote data seamlessly (with penalty)
- Amenable for fine-grain parallelism
- Distributed memory
- Explicit message passing
- Check UMA and NUMA
Message passing interface (MPI)
- Help library and application developer to create portable and high performance code more easily
- Allowing system vendors to utilize their specialized hardware features
Collective operations (CO)
- An important subset of the MPI standards.
- Operations used to exchange the information among a group of processors
- Commonly used bottleneck
- Performance depends on….
- System properties
- Algorithm and internal parameters =
Method(eg. segment sizes)
Performance improvement of MPI-COs
- Run-time collective method selection process
- Used ….
- Performance models
- Contains 105 performance models for 35 different collective algorithms
- Graphical encoding
- Statistical learning
- Performance models
- To automatically build adaptable, efficient, and fast run-time decision functions
- Covered
FastEthernet,GigE,MX,Infiniband,Cray specific Portals
Ch2. Message Passing Interface
2.1 MPI Standrad
-
MPI-1 standard (MPI Forum, 1995)
• Point-to-point communication
• (Intercommunicator) Collective operations
• Process groups
• Communication contexts (communicators)
• Process topologies
• Bindings for FORTRAN 77 and C
• Environmental Management and inquiry
• Profiling interface - MPI-1.2 standard (MPI Forum, 1997) includes …
• One-sided / Explicit shared-memory operations- I/O functions
• Dynamic process management
• Explicit support for threads
• Bindings for C++
- I/O functions
- MPI-2 standard (MPI Forum, 1997) includes …
- Intracommunicator collective operations (between two communicators)
2.2 MPI collective operations
-
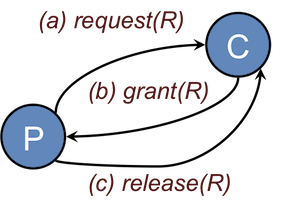
Barrier :
- Synchronization routine. Block the caller process until all process have reached this synchronization point
-
Broadcast :
- Broadcast from a root process to all processes
-
Scatter :
- Scatter from a root process to all processes
- $i^{th}$ block of data is sent to $i^{th}$ process
- Inverse operation of Gather
- Similar to vector transposition from rowvec (data in a process) to colvec (data with same index)
-
Gather :
- Gather data ordered by process rank to root process
- Similar to vector transposition from colvec to rowvec
-
All-Gather :
- Same with Gather, except that the result of the operations is available on all processes
- Gather followed by Broadcast
-
All-to-All :
- Total exchange among the processes
- Send to all, receive from all
- eg.
- a process $r$ sends block $j$ to a process $j$
- the process $j$ receives it as the block $r$
- Scatter for all rowvecs
- Similar to matrix transposition
-
Reduce :
- Combine the elements in the send buffer of all processes using a specified operation
- Result is stored in the $recvbuf$ at the root process
-
Reduce-Scatter :
- Reduce followed by Scatter
-
All-Reduce :
- Reduce followed by Broadcast
-
Scan :
- Prefix reduction across the processes
- The receive buffer at process $k$ holds reduction of the values in the send buffers of processes with ranks $0$ ~ $k$
-
ExScan :
- Exclusive scan : reduction of values with ranks $0$ ~ $(k-1)$
-
All-to-All-w :
- Generalized All-to-All
- Each process receives messages with different data-size and data-type from others
| MPI-CO | Illustration |
|---|---|
| Broadcast | 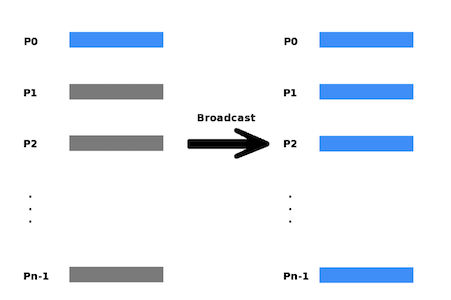 |
| Scatter | 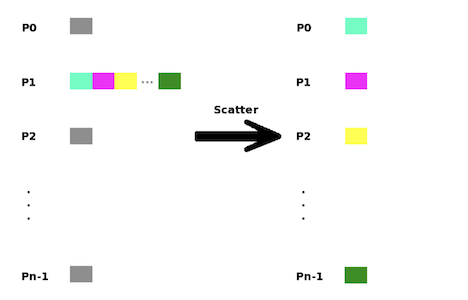 |
| Gather | 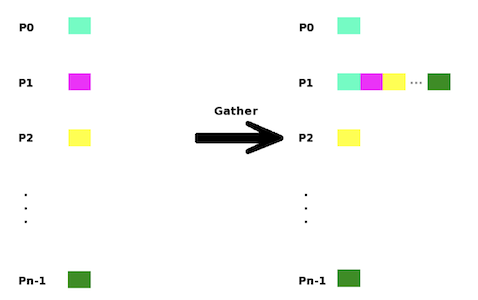 |
| AllGather | 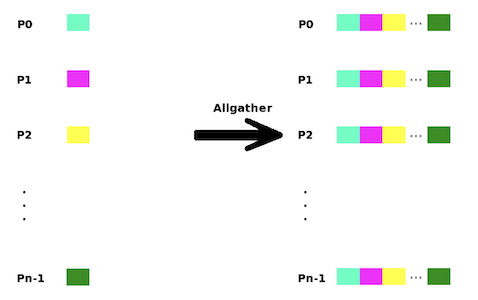 |
| AlltoAll | 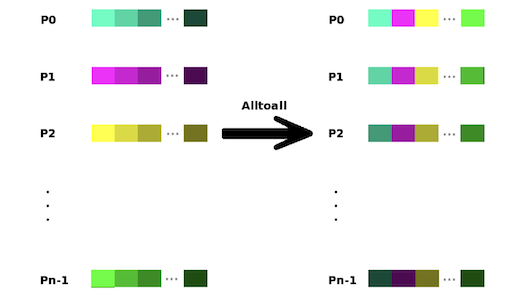 |
| Reduce | 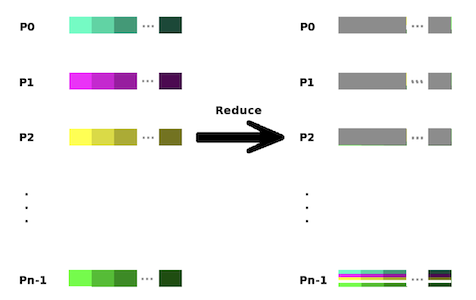 |
| AllReduce | 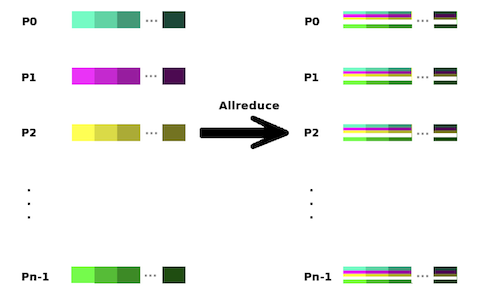 |
| ReduceScatter | 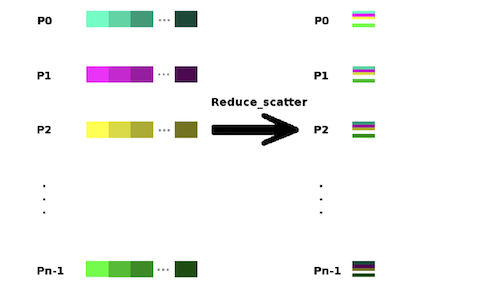 |
| Scan | 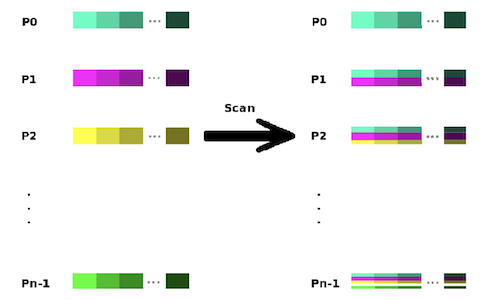 |
| ExScan | 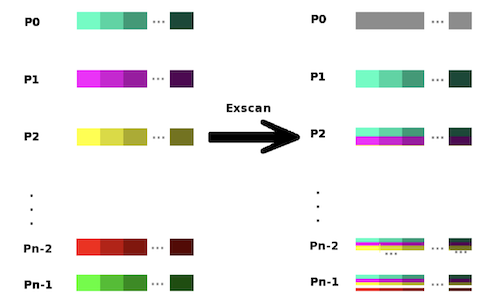 |
Ch.3 Literature Review
3.1 MPI-implementation and COs
-
MPICH algorithms
-
allreduce: recursive doubling, Rabenseifner’s algorithm, and reduce + broadcast.
• reduce: binomial tree and Rabenseifner’s algorithm.
• allgather: bruck, recursive doubling, and ring algorithms.
• alltoall: bruck, linear, and two versions of pairwise exchange (for power-of-two and non-power-of-two process case).
• broadcast: binomial tree, scatter + allgather (implemented in number of ways).
• barrier: bruck (dissemination algorithm).
-
allreduce: recursive doubling, Rabenseifner’s algorithm, and reduce + broadcast.
-
FT(fault tolerant)-MPI
- In the case of failure, FT-MPI can
- abort the job (non-FT behavior),
- respawn the dead process,
- shrink/resize the application to remove the missing processes, or
- leave the application as is, and
- create holes in the MPI COMM WORLD communicator.
- So, ensures that the in-flight messages will be either canceled or received.
- In the case of failure, FT-MPI can
-
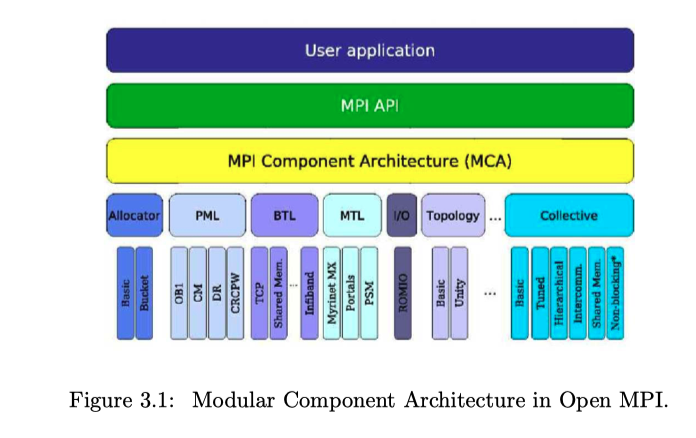
OpenMPI
- an open source, peer reviewed, high-performance, production quality MPI implementation.
- Three layers using modula component architecture (MCA)
- MPI layer: implements MPI semantics
- Run-time environment: provides a resource manger, global data store, messaging layer, a peer discovery system
- Portability layer: useful functions and data structures
- Components in collective framework of OpenMPI
- Basic, Self, Tuned, Hierarchical, Shared memory, Non-blocking
-
COs in hardware
- High performance networks
- Myrinet’s
MX, Open Fabrics (Infiniband), andQuadrics
- Myrinet’s
- Network interface cards (NICs)
- Offload protocol processing from the host CPU
- Bypass the OS
- Interact directly with MPI processes
- Point-to-point communication
- NIC-based COs
- Better than software implementation based on point-to-point comm (comm = communication)
- More consistent performance than software-based approach
- Not subject to CPU scheduling
- Worse for some hardware-based collectives
- IBM’s Blue Gene/L
- Multiple networks in a system
- Torus network for point-to-point comm
- Collective network for optimized collectives and comm with I/O nodes
- Global interrupt network
- Detail
- Broadcast : mesh algorithm with torus network
- Multicast capability of torus network
- Packet level pipelining
- AlltoAll : linear algorithm
- Major limitation: used only on a fully system partition
- Broadcast : mesh algorithm with torus network
- Multiple networks in a system
- High performance networks
3.2 Parallel communication models
- Most commonly used parallel comm models:
- Grama, Ananth, et al. Introduction to parallel computing, 2003.
- Introduced basic collective comm operations
- Message splitting
-
Hockney :
- To assess the performance of allgather, broadcast, all-to-all, reduce-scatter, reduce, and allreduce collectives
-
LogP/LogGP :
- To find an optimal algorithm and parameters for topology-aware collective operations incorporated in the MagPIe library
-
PLogP:
- To evaluate performance of broadcast and scatter operations on intra-cluster communication.
- Grama, Ananth, et al. Introduction to parallel computing, 2003.
3.3 Algorithm selection and automatic tuning
- Exhaustive testing
- Statistical learning methods
- Support vector methods
- Bayesian decision rule approach
- Markov decision process
- (Non)-parametric (geometric) modeling
Ch.4 Parallel Communication Models
4.1 Algorithms for MPI COs
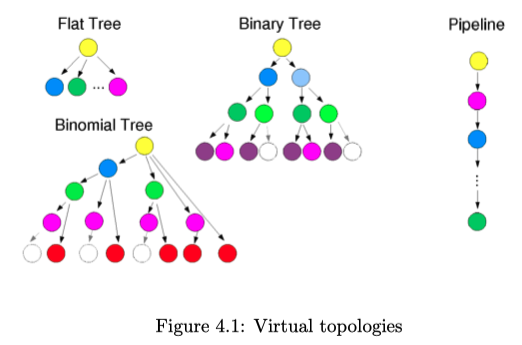
1. Virtual topologies
-
Classification by data direction
- One-to-many
- Broadcast
- Scatter
- Many-to-one
- Reduce
- Gather
- Many-to-many
- Barrier
- All-to-All
- All-Reduce
- All-Gather
- Expressed as unidirectional data flow:
- receive data from preceding node(s),
- process data, if required,
- send data to succeeding node(s).
- One-to-many
-
Virtual topologies determine the preceding and succeeding nodes in the algorithm
- Goal: Grow balanced trees
- Sometimes less balanced trees are beneficial4
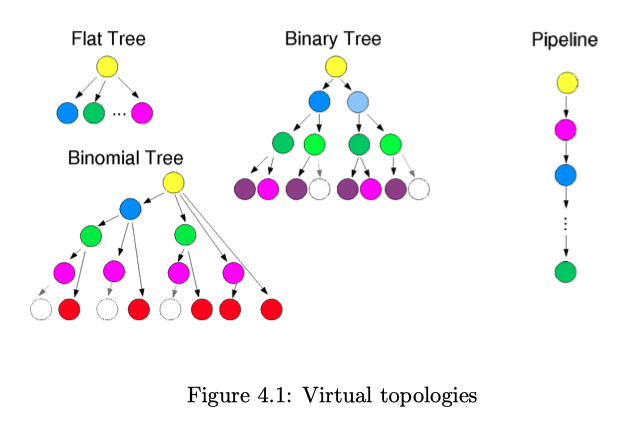
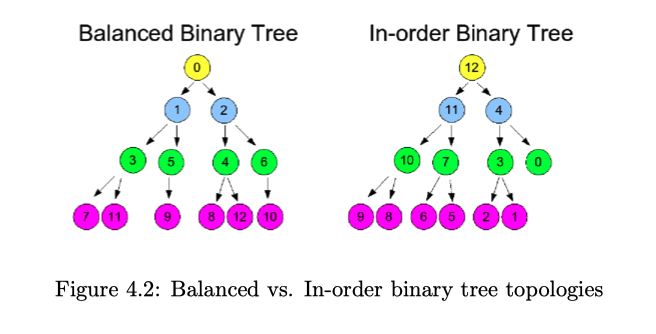
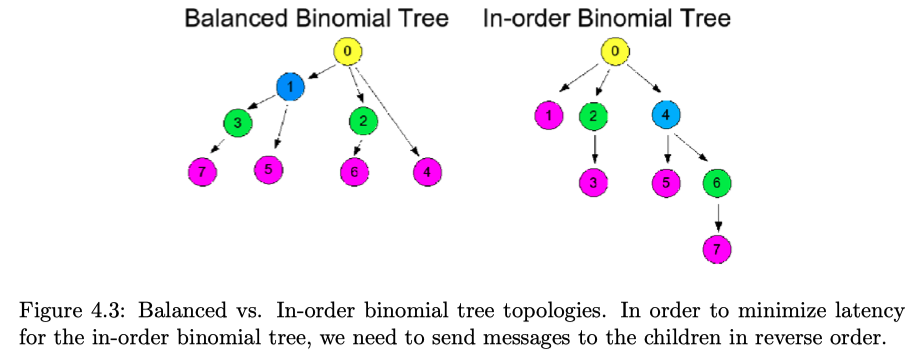
2. Collective Algorithms
This section discusses different algorithms for MPI collective operations.
-
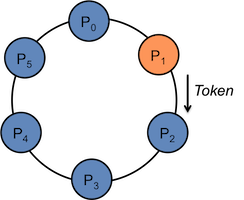
Barrier
- Double Ring (Token ring algorithm)
- 2 P steps (P : the number of processes in the communicator)
- Fan-in-fan-out (Central server algorithm)
- 2P messages
- Zero-byte gather operation followed by zero-byte broadcast operation
- Then, total number of messages: O(P) $\rightarrow$ O($log_2(P)$)
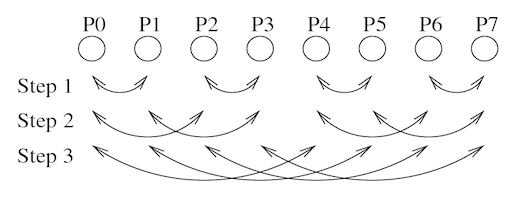
- Recursive doubling (figure)
- O($log_2(P)$) steps
- At step $k$, rank $r$ exchanges a zero-byte message with rank ($r$ $XOR$ $2^k$ ).
- At the end of $log_2 (P)$ steps, the algorithm guarantees that all processes have entered the barrier, and thus everyone is allowed to leave.
- Need more steps when P is not exact power of two.
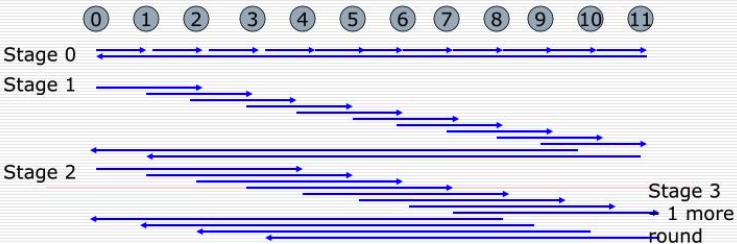
- Bruck / Dissemination algorithm (figure)
- O($log_2(P)$) = $\lceil log_2(P) \rceil$ steps, regardless of P.
- At the step $k$, process $r$ sends a message to rank $(r + 2^k )$ and receives message from rank $(r − 2^k )$ with wrap around.
- Double Ring (Token ring algorithm)
-
Broadcast
- Generalized broadcast with virtual topologies
- Implements a broadcast operation as a communication pipeline
- For all message segments, process $r$ receives the segment $s$ from the parent $parent(r)$, and forwards it to all of its children $children(r)$.
- Virtual topologies: pipeline, flat tree, binomial tree
- Split-binary tree algorithm
- An optimization of the regular binary tree broadcast algorithm
- Split message in half, send left and right halves down to left and right sub-trees, respectively.
- Last leaves should find the other half from the process with opposite rank (or from the root)
- Effect: Half bandwidth with one more step
- Generalized broadcast with virtual topologies
-
Scatter(v)
- Linear algorithm
- Binomial algorithm
-
Gather(v)
- Linear algorithm without synchronization
- Linear algorithm with synchronization
- Binomial algorithm
-
Allgather(v)
- Gather + Broadcast
- Bruck
- Recursive doubling
- Ring
- Neighbor exchange
-
Alltoall(v/w)
- Linear without synchronization
- Linear with synchronization
- Pairwise exchange
- Bruck algorithm
-
Reduce
- Generalized reduce with virtual topologies
- Rabenseifner’s algorithm and its variations
-
Reduce-scatter
- Reduce + scatterv
- Recursive halving algorithm
- Ring
-
Allreduce
- Reduce + Broadcast
- Recursive doubling
- Rabenseifner’s algorithm
- Ring without segmentation
- Ring with segmentation
-
Scan
- Linear without segmentation
- Linear with segmentation
- Binomial algorithm
- Exscan
To be updated …
4.2 Parallel communication models
1. Modeling point-to-point communication
-
Hockney model
-
LogP/LogGP models
-
PLogP model
2. Modeling computation
4.3 Performance models of MPI collective operations
1. Building a performance model: split-binary broadcast
-
Hockney model
-
LogP/LogGP models
-
PLogP model
2 . Building a performance model: linear gather with synchronization
-
Hockney model
-
LogP/LogGP models
-
PLogP model
3. Building a performance model: recursive doubling allgather
-
Hockney model
-
LogP/LogGP models
-
PLogP model
4. Performance models of collective algorithms
4.4 Evaluation of MPI collective operation models
1. Model parameters
2. Performance of different collective algorithms
-
Barrier performance
-
Reduce performance
-
Alltoall performance
3. Final comments about parallel computation models
Reference
- Jelena Pjesivac-Grbovic’s PhD Thesis: “Towards Automatic and Adaptive Optimizations of MPI Collective Operations”, University of Tennessee, 2007
- Thakur, Rajeev, Rolf Rabenseifner, and William Gropp. “Optimization of collective communication operations in MPICH.“ The International Journal of High Performance Computing Applications 19.1 (2005): 49-66.
Notes Mentioning This Note
Table of Contents
- Towards Automatic and Adaptive Optimizations of MPI Collective Operations
- Abstract
- Ch.1 Introduction
- Ch2. Message Passing Interface
- Ch.3 Literature Review
- Ch.4 Parallel Communication Models
- Reference