Multiprocessors and Thread-Level Parallelism
- Chapter 5 in Computer Architecture A Quantitative Approach (6th) by Hennessy and Patterson (2017)

Introduction
The increased importance of multiprocessing reflects several major factors:
- Inefficiency of adding more instruction-level parallelism?
- $\rightarrow$ Multiprocessing = Only scalable and general-purpose way
- A growing interest in high-end servers as cloud computing and software-as-a-service
- A growth in data-intensive applications
- Increasing performance on the desktop is less important
- Highly compute- and data-intensive applications are being done on the cloud
- An improved understanding of how to use multiprocessors effectively
- The advantages of leveraging a design investment by replication rather than unique design
In this chapter, we focus on exploiting thread-level parallelism (TLP). TLP implies the existence of multiple program counters and thus is exploited primarily through MIMDs.
Our focus in this chapter is on multiprocessors, which we define as computers consisting of tightly coupled processors:
- Whose coordination and usage are typically controlled by a single operating system and
- That share memory through a shared address space.
Such systems exploit thread-level parallelism through two different software models:
- The execution of a tightly coupled set of threads collaborating on a single task, which is typically called parallel processing
- The execution of multiple, relatively independent processes that may originate from one or more users, which is a form of request-level parallelism (See Chapter 6 [[ Warehouse-Scale Computer ]])
- Maybe exploited by a single application running on multiple processors, such as a database responding to queries,
- Or multiple applications running independently, often called multiprogramming.
Multithreading?
- A technique that supports multiple threads executing
- In an interleaved fashion on a single multiple-issue processor
- Many multicore processors also include support for multithreading
Our focus will be on multiprocessors with roughly 4–256 processor cores, which might occupy anywhere from 4 to 16 separate chips;
- Multicore?: Multiprocessors in a single chip
Larger scale computers?
- See Chapter 6 [[ Warehouse-Scale Computer ]]
- Clusters: Large-scale systems for cloud computing
- Warehouse-scale computers: Extremely large clusters
-
Multicomputer:
- Less tightly coupled than the multiprocessors
- More tightly coupled than warehouse-scale systems
- Primary use for high-end scientific computation
Multiprocessor Architecture: Issues and Approach
To take advantage of an MIMD multiprocessor with $n$ processors, we must usually have at least $n$ threads or processes to execute;
- With multithreading, that number is 2–4 times higher.
The independent threads within a single process are:
- Identified by the programmer or
- Created by the operating system (from multiple independent requests) or
- Generated by a parallel compiler exploiting data parallelism in the loop
Grain size:
- The amount of computation assigned to a thread
Thread for data-level parallelism?
- Possible, but, with higher overhead than SIMD processor or GPU due to its small grain size
Two classes of shared-memory multiprocessors (SMP vs DSM architectures ):
-
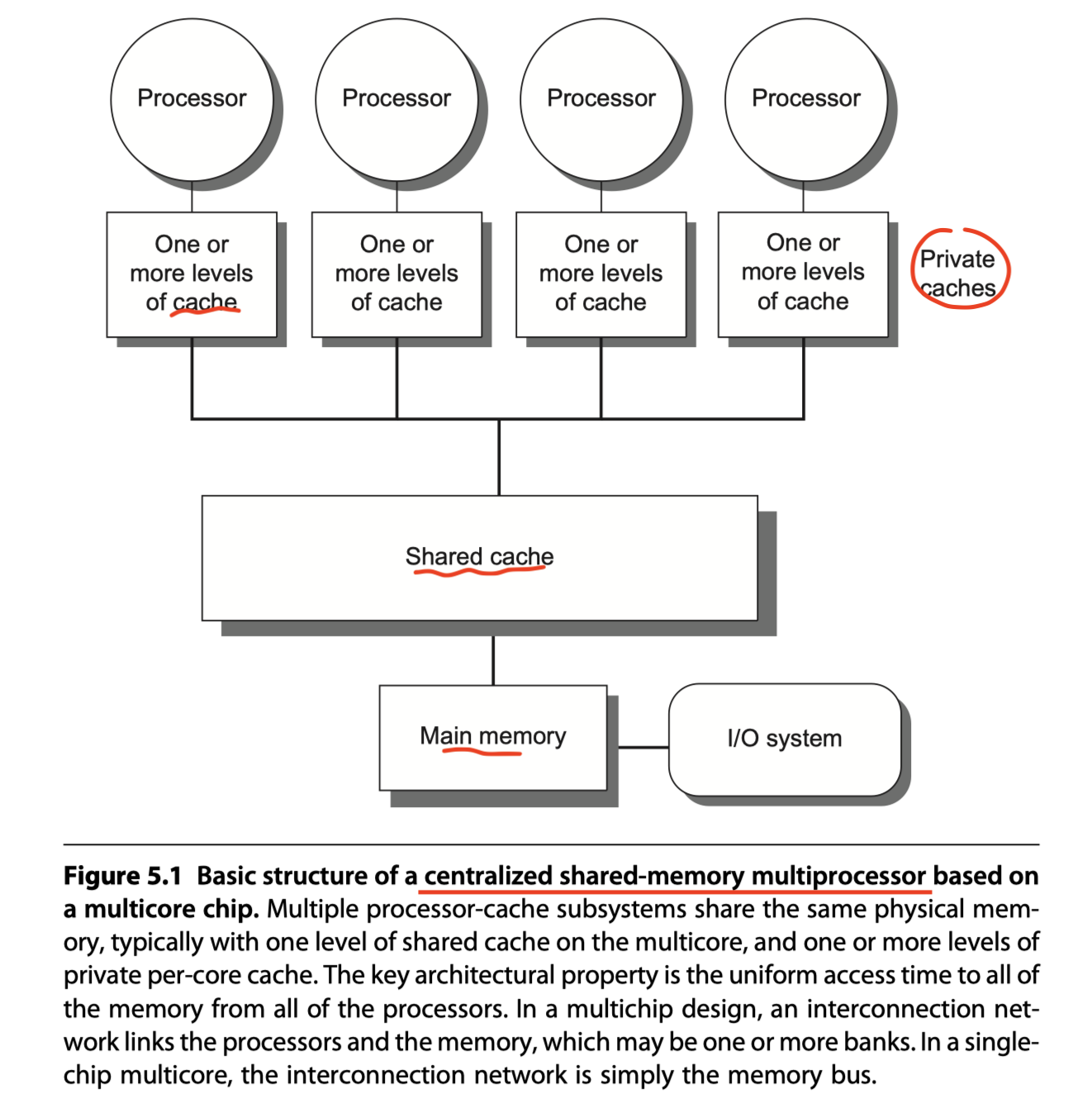
Symmetric (shared-memory) multiprocessors (SMPs) in Figure 5.1
- Centralized shared-memory multiprocessors
- Small to moderate number of cores $\leq 32$
- The processors share a single centralized memory
- All processors have equal access $\rightarrow$ symmetric!!
- Most existing multicores are SMPs, but not all.
-
Uniform memory access (UMA):
- All processors have a uniform latency from memory
- Even if the memory is organized into multiple banks
-
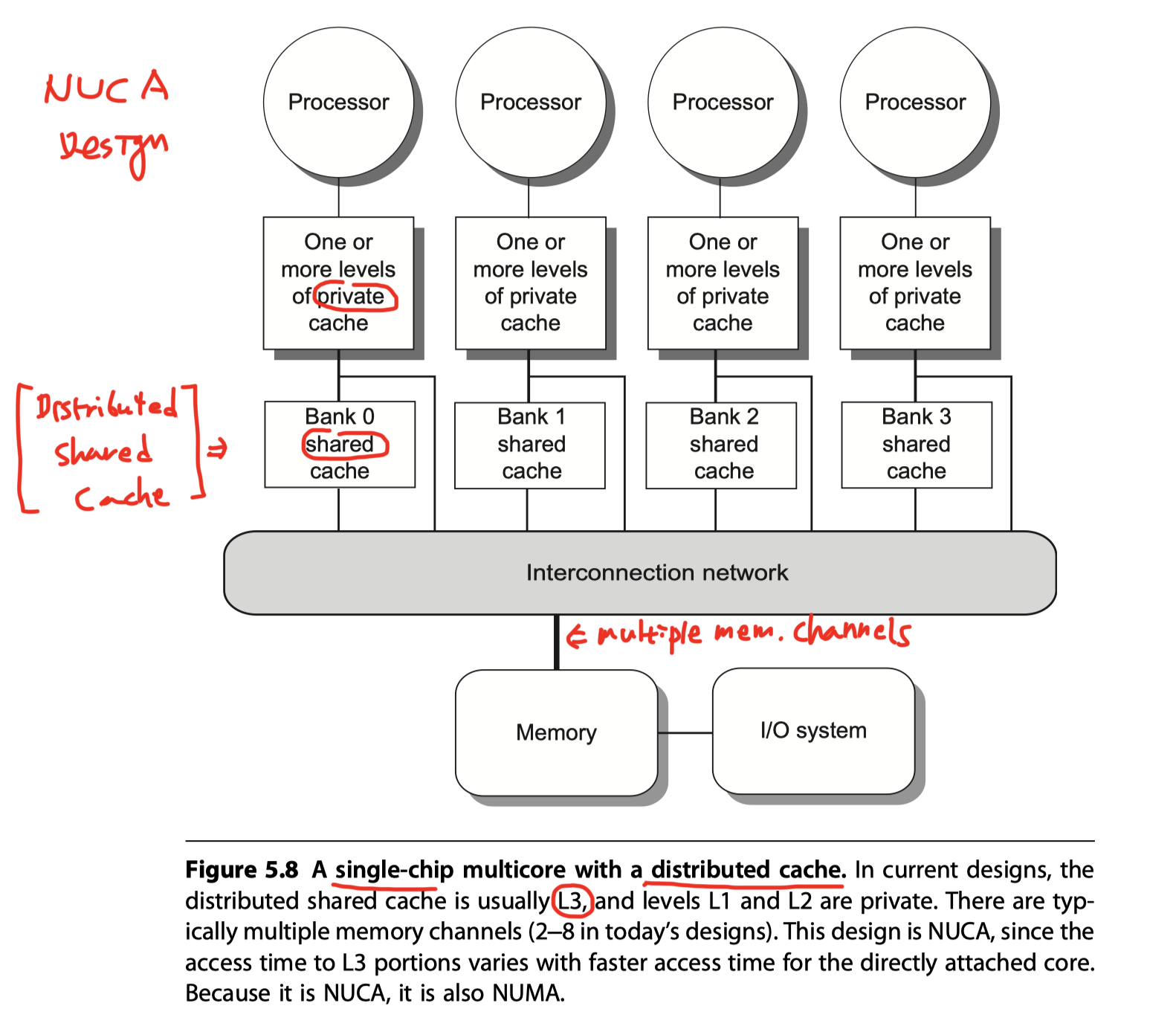
Nonuniform Cache Access (NUCA):
- Some multicores have nonuniform access to the outermost cache, a structure called NUCA for Nonuniform Cache Access, and are thus are not truly SMPs, even if they have a single main memory.
- IBM Power8: Distributed L3 caches with nonuniform access time to different addresses in L3
-
Multiprocessors consisting of multiple multicore chips?
- Because an SMP approach becomes less attractive with a growing number of processors,
- Often separate memories for each multicore chip $\rightarrow$ Some form of distributed memory
-
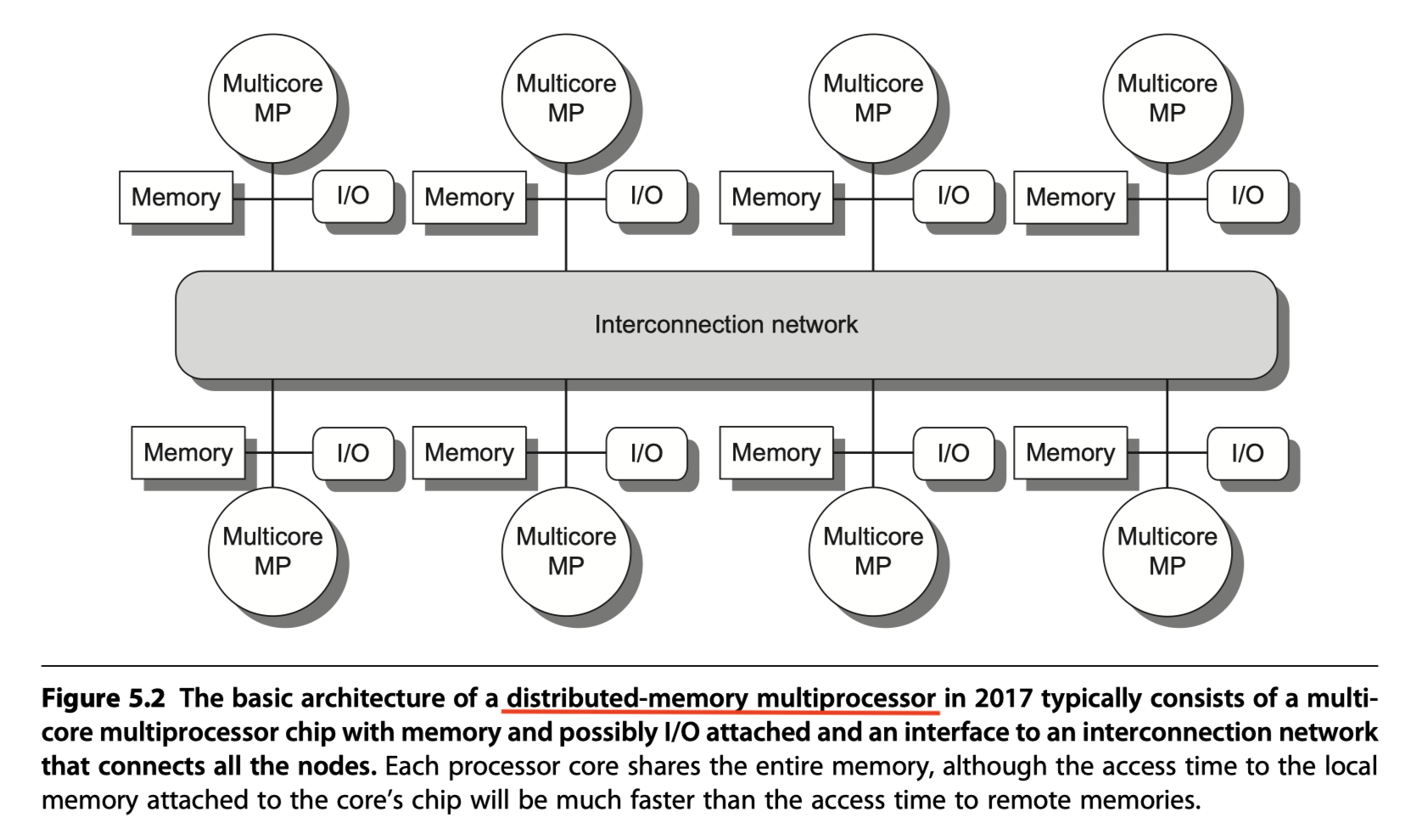
Distributed shared memory (DSM) in Figure 5.2
- To support larger processor counts
- Must be distributed among the processors
- The larger number of processors also raises the need for a high-bandwidth interconnect (See Appendix F)
- Directed networks (i.e. switches)
- Indirect networks (eg. multidimensional meshes)
- Distributing the memory among the nodes both increases the bandwidth and reduces the latency to local memory
-
Nonuniform memory access (NUMA):
- The access time depends on the location of a data word in memory
-
Key disadvantages:
- Communicating data among processors becomes somewhat more complex
- DSM requires more effort in the software
Shared memory:
- In both SMP and DSM architectures,
- The address space is shared by all the processors!
- Communication among threads occurs through a shared address space
-
i.e. A memory reference can be made by any processor to any memory location,
- Assuming it has the correct access rights
How about larger scale architectures?
- Clusters and warehouse-scale computers
- Look like individual computers connected by a network
- Memory of one processors cannot be accessed by another processor
- Without the assistance of software protocols running on both processors
- So, need message-passing protocols!!
Challenges of Parallel Processing
The first hurdle: Insufficient parallelism
Amdahl’s Law:
- To achieve a speedup of 80 with 100 processors,
- Only 0.25% of the original computation can be sequential!

The second major challenge: Large latency of remote access in a parallel processor;
- Communication latency
- Between separate cores: 35–50 clock cycles
- Among cores on separate chips: 100 ~ More than 300 clock cycles
- Depending on the communication mechanism, the type of interconnection network, and the scale of the multiprocessor.
- Example
- Multiprocessor with 4GHz clock rate
- 100ns delay to handle a reference to a remote memory
- All local access hit cache
- Base CPI = 0.5
- CPI with 0.2% remote communication reference?
- 0.5 +0.2% $\times$ Remote request cost = 1.3
- $\rightarrow$ Multiprocessor with all local references is 1.3/0.5 = 2.6 times faster
Centralized Shared-Memory Architectures
The observation that the use of large, multilevel caches can substantially reduce the memory bandwidth demands of a processor is the key insight that motivates centralized memory multiprocessors.
Access to memory is asymmetric in multiprocessors:
- Faster to the local memory
- Slower to the remote memory
Symmetric shared-memory machines support the caching of both …
-
Private data used by a single processor
- Cached like a uniprocessor
-
Shared data used by multiple processors
- Cache coherence problem!
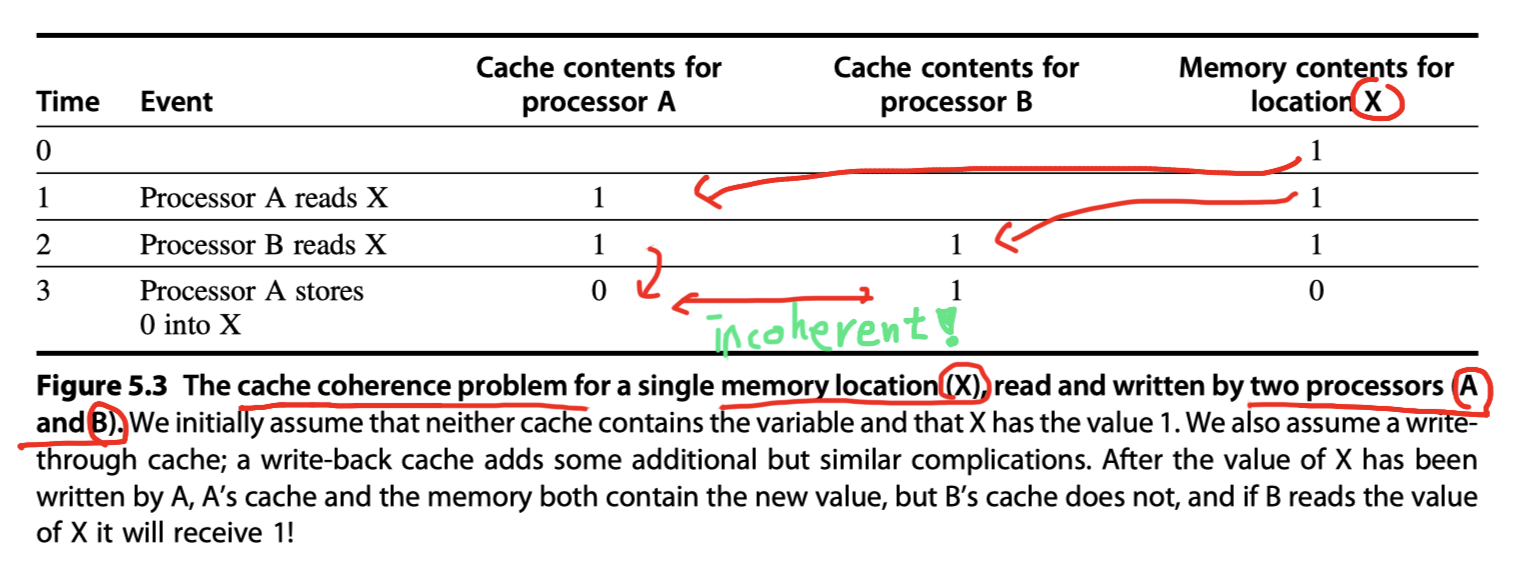
What Is Multiprocessor Cache Coherence?
Cache coherence problem:
- Because the view of memory held by two different processors is through their individual caches,
- The processors could end up seeing different values for the same memory location!
- i.e. Local states in private caches vs Global state in shared cache or main memory
Two different aspects of memory system behavior:
-
Coherence
- Defines what values can be returned by a read
-
Consistency
- Determines when a written value will be returned by a read
A memory system is coherent if: (P = Processor, P’ = Another processor, X = Memory location)
-
Preserve program order:
- Write by P to X $\rightarrow$ Read by P to X $\rightarrow$ Always returns the value written by P
- If no writes of X by P’ when P writes and reads
- True in even uniprocessors
-
Have a coherent view of memory:
- Write by P’ to X $\rightarrow$ Read by P to X $\rightarrow$ Returns the written value by P’
- If the read and write are sufficiently separated in time and no other writes to X occur between the two accesses
- Write by P’ to X $\rightarrow$ Read by P to X $\rightarrow$ Returns the written value by P’
-
Write serialization:
- Writes to the same location are serialized
- Two writes to the same location by any two processors are seen in the same order by all processors.
- For example, if the values 1 and then 2 are written to a location, processors can never read the value of the location as 2 and then later read it as 1.
Memory consistency model:
- The question of when a written value will be seen is also important.
- Observe that
- We cannot require that a read of X instantaneously see the value written for X by some other processor.
- For example,
- If a write of X on one processor precedes a read of X on another processor by a very small time,
- It may be impossible to ensure that the read returns the value of the data written,
- Since the written data may not even have left the processor at that point.
Coherence and consistency are complementary:
- Coherence defines the behavior of reads and writes to the same memory location
- Consistency defines the behavior of reads and writes with respect to accesses to other memory locations
Assume from now until Section 5.6 (Memory Consistency Model)
- First, a write does not complete (and allow the next write to occur) until all processors have seen the effect of that write.
- Second, the processor does not change the order of any write with respect to any other memory access.
- These two conditions mean that, if a processor writes location A followed by location B, any processor that sees the new value of B must also see the new value of A
Basic Schemes for Enforcing Coherence
A program running on multiple processors will normally have copies of the same data in several caches. In a coherent multiprocessor, the caches provide both
-
Migration
- A data item can be moved to a local cache and used there in a transparent fashion
- Reduces both the latency to access a shared data item that is allocated remotely and the bandwidth demand on the shared memory
-
Replication of shared data items
- Reduces both latency of access and contention for a read shared data item
Cache coherence protocols:
- Multiprocessors adopt a hardware solution by introducing a protocol to maintain coherent caches, that supports migration and replication.
- Key idea = “Tracking the state of any sharing of a data block”
- Two classes of protocol in use
- Directory based
- Snooping
Directory based:
- The sharing status of a particular block of physical memory is kept in one location, called the directory
-
Two very different types of directory-based cache coherence
- (1) One centralized directory in an SMP
- (2) Distributed directories in a DSM (See Section 5.4)
Snooping:
- Each cache tracks sharing status of memory blocks they store.
- In SMP, the caches are typically all accessible via some broadcast medium (a bus connects the per-core caches to the shared cache or memory)
- All cache controllers monitor or snoop on the medium to determine whether they have a copy of a block that is requested on a bus or switch access.
-
Snooping can also be used as the coherence protocol for a multichip multiprocessor, and some designs support a
- Snooping protocol on top of a directory protocol within each multicore.
Snooping Coherence Protocols
Two ways to maintain the coherence requirement:
- Write invalidate protocol
- Write update or write broadcast protocol
Write invalidate protocol:
- Ensure that a processor has exclusive access to a data item before writing that item
- It invalidates other copies on a write
- The most common protocol
- For a write,
- We require that the writing processor has exclusive access,
- Preventing any other processor from being able to write simultaneously
-
Write serialization
- If two processors do attempt to write the same data simultaneously, one of them wins the race
- Causing the other processor’s copy to be invalidated
- For the other processor to complete its write,
- It must obtain a new copy of the data, which must now contain the updated value.
- If two processors do attempt to write the same data simultaneously, one of them wins the race

Write update or write broadcast protocol:
- Must broadcast all writes
- Consumes considerably more bandwidth
- Virtually all recent multiprocessors have opted to implement a write invalidate protocol
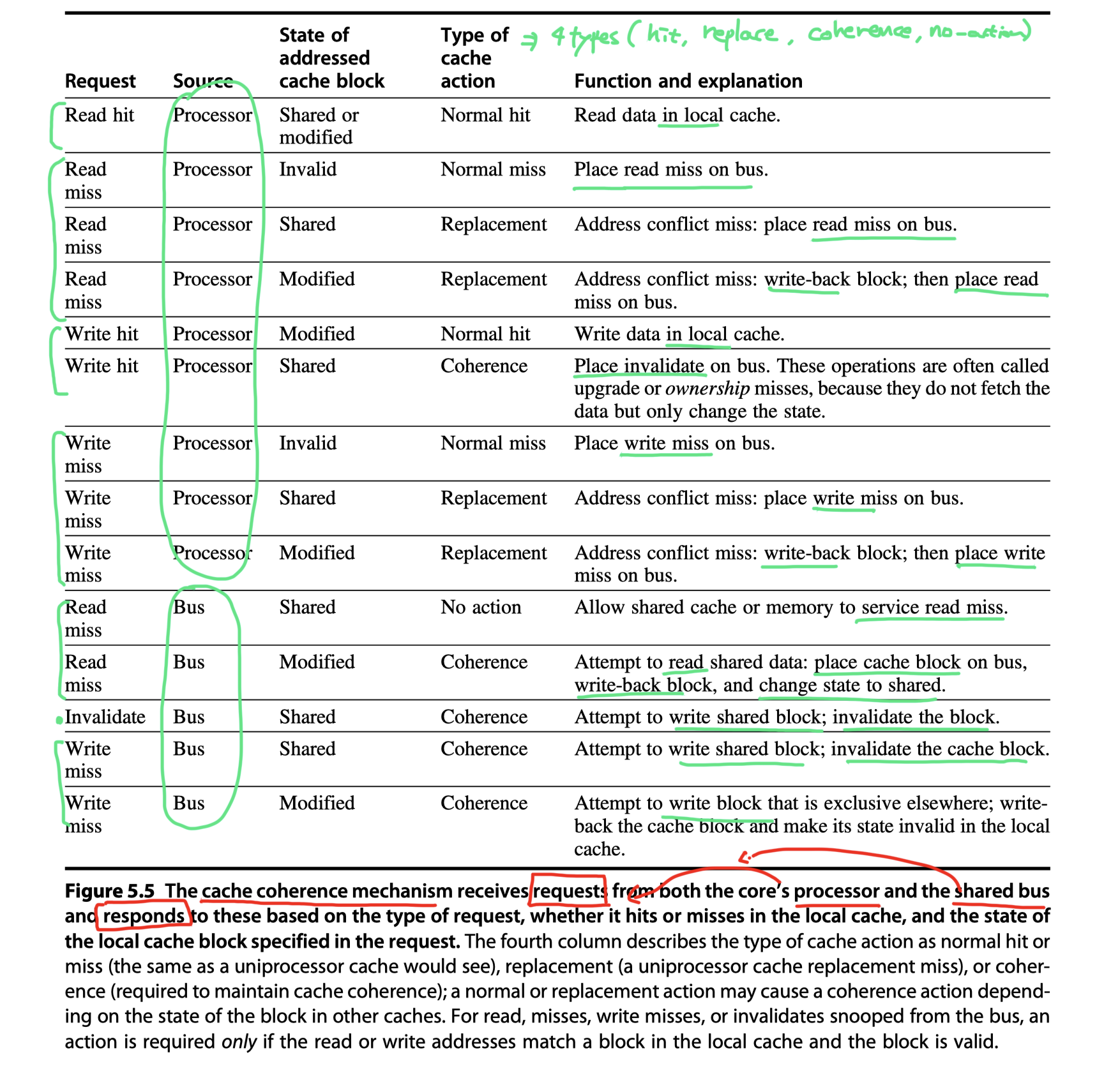
Basic Implementation Techniques
Implementing an invalidate protocol?
- Use of the bus to perform invalidate
- Or another broadcast medium
- In older multiple-chip multiprocessors,
- The bus used for coherence is the shared-memory access bus
- In a single-chip multicore,
- The bus can be the connection between the private caches (L1 and L2 in the Intel i7) and the shared outer cache (L3 in the i7).
- To perform an invalidate,
- The processor simply (1) acquires bus access and (2) broadcasts the address to be invalidated on the bus.
- All processors continuously (3) snoop on the bus, watching the addresses.
- The processors (4) check whether the address on the bus is in their cache. If so, the corresponding data in the cache are (5) invalidated.
Two processors attempt to write shared blocks at the same time?
- Do write serialization!
- The first processor to obtain bus access will cause
- Any other copies of the block it is writing to be invalidated
- The core with the sole copy of a cache block is normally called the owner of the cache block
Things to implement:
- How to obtain bus access
- How to enforce write serialization
- How to invalidate outstanding copies of a cache block that is being written into
- Use a valid bit of each cache block
- How to locate a data item when a cache miss occurs in a write-back cache
- For a write-through cache, simply fetch the most recent value from the memory
- For a write-back cache,
- The most recent value of a data can be in a private cache!
- Use the same snooping scheme both for cache misses and for writes
-
Cache misse steps:
- (1) A cache miss occurred in a requestor P
- The owner P’ (2) snoops the read request from the requestor P to the memory (or L3)
- If the owner P’ has updated the request cache block, and it has (3) a dirty bit
- Then, the owner P’ …
-
(4) Provides the cache block in response the read request
- If the owner P’ owns the cache block exclusively
- Change the state of the cache block (5) from exclusive (unshared) to shared
- Causes the memory (or L3) (6) access to be aborted
-
(4) Provides the cache block in response the read request
- The requestor (7) gets the copy of the cache block
-
Write steps:
- Q. Any other copies of the block are (1) cached?
- Check a bit indicating whether the block is shared
- No $\rightarrow$ The write does not need to be placed on the bus in a write-back cache
-
Yes $\rightarrow$
- (2) Generate an invalidate on the bus
- Marks the block as (3) exclusive (unshared)
- Q. Any other copies of the block are (1) cached?
Every bus transaction must check the cache-address tags, which could potentially interfere with processor cache accesses. How to reduced the interference? :
- (Approach#1) Duplicate the tags (just to allow checks in parallel with CPU) and have snoop accesses directed to the duplicate tags
- (Approach#2) Use a directory at the shared L3 cache
- Then, invalidates can be directed only to those caches with copies of the cache block.
- This requires that L3 must always have a copy of any data item in L1 or L2, a property called inclusion
An Example Protocol
Finite-state controller in each core:
- Responds to requests from the processor in the core and from the bus
- Changes the state of the selected cache block
- Use the bus to
- Access data
- Invalidate the data
The simple protocol we consider has three states:
- invalid
- shared: Indicates that the block in the private cache is potentially shared,
- modified: Indicates that the block has been updated in the private cache, so exclusive
A finite-state transition diagram for a single private cache block using a write invalidation protocol and a write-back cache:
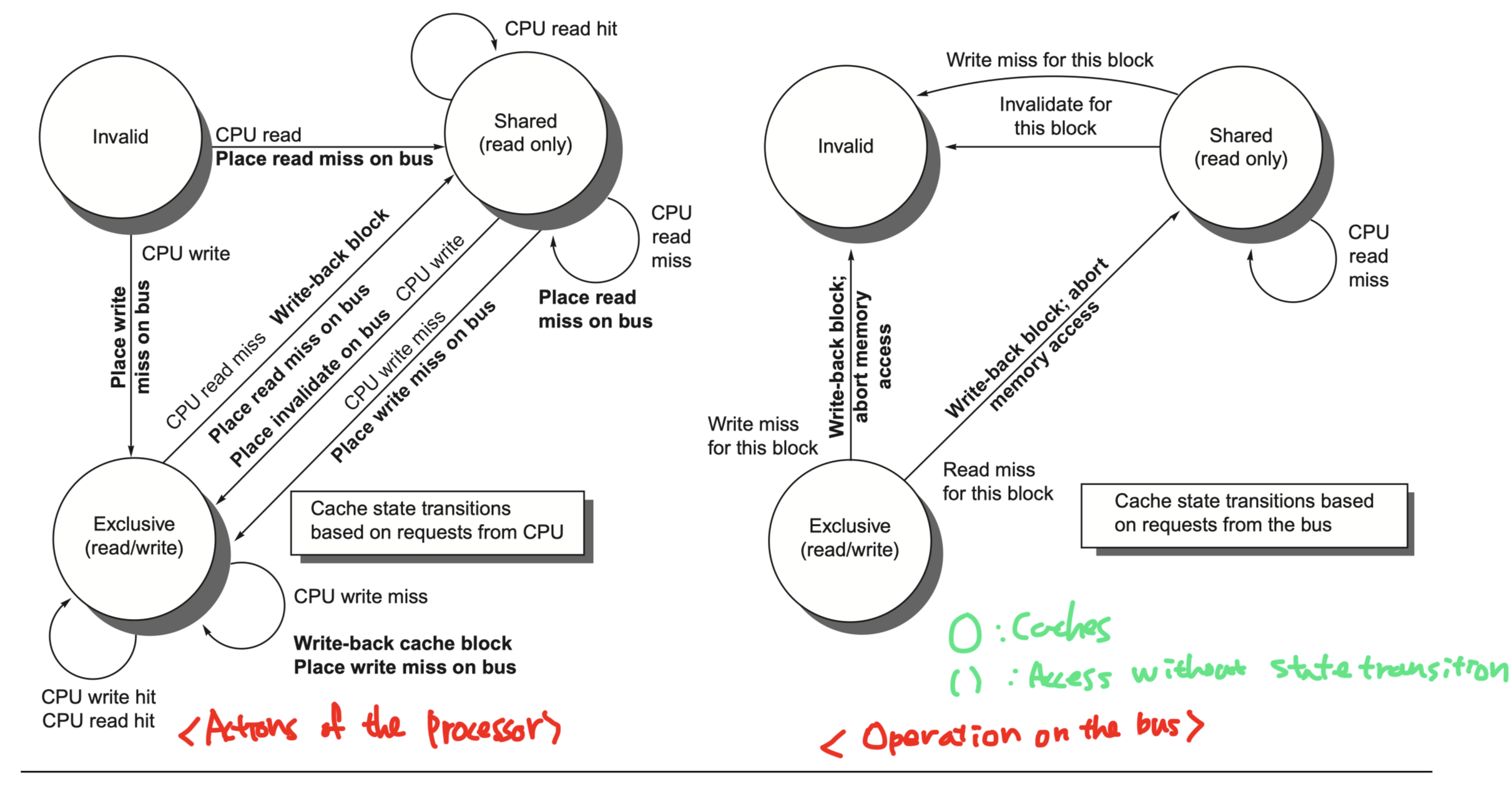

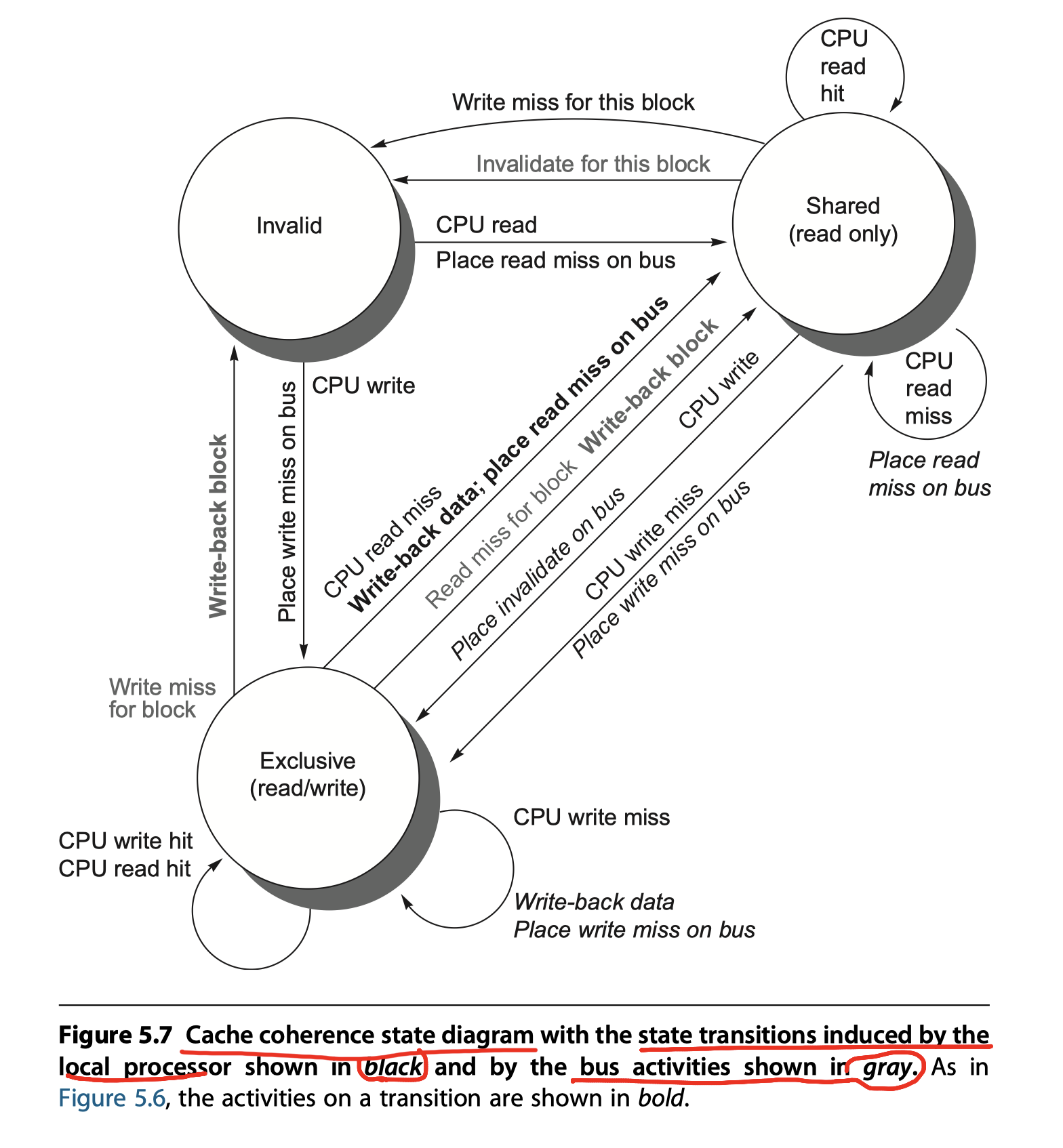
The most important assumption so far is that the protocol assumes that operations are atomic—that is, an operation can be done in such a way that no intervening operation can occur.
- For example, the protocol described assumes that write misses can be detected, acquire the bus, and receive a response as a single atomic action.
-
In reality this is not true. In fact, even a read miss might not be atomic;
- After detecting a miss in the L2 of a multicore,
- The core must arbitrate for access to the bus connecting to the shared L3.
- Nonatomic actions introduce the possibility that the protocol can deadlock,
- Meaning that it reaches a state where it cannot continue.
Hardware implementation:
-
Single-chip multicore processors
- $\rightarrow$ snooping or simple central directory protocol
-
Many multiprocessor chips
- eg. Intel Xeon, AMD Opteron with high-speed interface
- Usually have a distributed memory architecture and
- $\rightarrow$ Inter-chip coherency mechanism
- $\rightarrow$ Directory scheme
Extensions to the Basic Coherence Protocol
Basic protocol described so far:
-
MSI protocol
- Uses only three states such as
modified,shared, andinvalid(That why it’s called MSI)
- Uses only three states such as
-
Many extensions of this basic protocol
- Adding additional states and transactions
- (1) MESI: Modified, Exclusive, Shared, and Invalid
- (2) MOESI: Modified, Owned, Exclusive, Shared, and Invalid
Two of the most common extensions:
-
MESI
- Four states: Modified, Exclusive, Shared, and Invalid
- Exclusive state indicates that a cache block is resident in only a single cache but is clean
- In MSI protocol, this case was included the
Sharedstate - A block is in the E state
- It can be written without
- Acquiring bus access
- Generating any invalidates
- Which optimizes the case where a block is read by a single cache before being written by that same cache.
- It can be written without
-
MESIF
- A variant of MESI in Intel i7
- Adds a Forward state
- Designate which sharing processor should respond to a request
- Designed to enhance performance in distributed memory organizations
-
MOESI
- Five states: Modified, Owned, Exclusive, Shared, and Invalid
- Owned state : indicate that the associated block is owned by that cache and out-of-date in memory.
- In MSI and MESI,
- Attempt to share a block in the Modified state
- $\rightarrow$ Changed to Shared (in both the original and newly sharing cache)
- The block must be written back to memory
- In a MOESI protocol,
- Attempt to share a block in the Modified state
- $\rightarrow$ Changed to Owned state in the original cache
- Without writing it to memory
- Other caches with the data supplied from the owner $\rightarrow$ Shared state
- AMD Opteron
Limitations in Symmetric Shared-Memory Multiprocessors and Snooping Protocols
Increasing communication burden:
- #processors in multiprocessor $\uparrow$ ,
- Memory demands of each processor $\uparrow$,
$\rightarrow$ Any centralized resource can be bottleneck:
- Single shared bus
- Snooping bandwidth at the caches
Three different approaches:
- IBM Power8
-
8 parallel buses connect
- 12 processors in a single multicore
- Distributed L3 and
- Up to 8 separate memory channels
- Nonuniform access time for both L3 and memory
-
8 parallel buses connect
- Xeon E7
-
Three rings connect
- Up to 32 processors
- Distributed L3 cache
- Two/Four memory channels
- Not uniform, but
- Can operate as if access times were uniform
-
Three rings connect
- Fujitsu SPARC64X+
-
A crossbar to connect
- A shared L2
- To up to 16 cores and multiple memory channels
- Symmetric organization with uniform access time
-
A crossbar to connect
- Example
- Assumption:
- 8-processors where each processor has its own L1 and L2
- Snooping on a shared bus among L2s
- Average L2 request = 15 cycles
- Clock rate = 3.0 GHz, CPI = 0.7
- load/store frequency = 40%
- Question
- If our goal is that no more than 50% of the L2 bandwidth is consumed by coherence traffic, what is the maximum coherence miss rate per processor?
- Assumption:

Several techniques for increasing the snoop bandwidth:
- (1) Tags can be duplicated just to allow checks in parallel with CPU
- Doubles the effective cache-level snoop bandwidth
- Average cost of a CMR(coherence miss rate) decrease to 12.5cycles
- If 50% the coherence requests do not hit with 10 cycle snoop request cost
- (2) Each processor with distributed memory handles snoops individually and broadcast to L2 again for snoop hit
- Each processor has a portion of the memory
- Handles snoops for that portion of the address space
- NUCA design used by IBM 12-core Power8
- But effectively scales the snoop bandwidth at L3 by the #processors.
- Detail steps: If there is a snoop hit in L3, then we must still broadcast to all L2 caches, which must in turn snoop their contents.
- Since L3 is acting as a filter on the snoop requests, L3 must be inclusive
- Still need broadcast for snoop hit!!
- (3) Place a directory at the level of the outermost shared cache (eg. L3)
- L3 acts as a filter on snoop requests and must be inclusive
- We need not snoop or broadcast to all the L2s.
- Both L3 and the associated directory entries can be distributed
- Intel Xeon E7 series: 8~32 cores
-
Intermediate point between a snooping and a directory protocol
- Used in AMD Opteron
- Memory is directly connected to each multicore chip (Up to four multicore chips)
- NUMA: Nonuniform memory access
- Local memory is somewhat faster
- Opteron’s coherence protocol
- Point-to-point links (Not shared) to broadcast up to three other chips
- Not shared $\rightarrow$ Need explicit acknowledgment to know that invalidation operation has completed
- Uses a broadcast to find potentially shared copies,
- like a snooping protocol,
- But uses the acknowledgments to order operations,
- like a directory protocol
- Used in AMD Opteron
Directory-based protocols, which eliminate the need for broadcast to all caches on a miss? See Section 5.4
- Directories within the multicore (Intel Xeon E7) or
- Add directories when scaling beyond a multicore
Implementing Snooping Cache Coherence
The major complication in actually implementing the snooping coherence protocol we have described is that write and upgrade misses are not atomic in any recent multiprocessor.
- In a multicore with a single bus,
- these steps can be made effectively atomic
- by arbitrating for the bus to the shared cache or memory first (before changing the cache state) and
- not releasing the bus until all actions are complete.
-
Without a single, central bus,
- we must find some other method of making the steps in a miss atomic.
- In particular, we must ensure that two processors that attempt to write the same block at the same time, a situation which is called a race, are strictly ordered:
- one write is processed and precedes before the next is begun.
-
In a multicore using multiple buses,
- races can be eliminated if each block of memory is associated with only a single bus,
- ensuring that two attempts to access the same block must be serialized by that common bus.
- This property, together with the ability to restart the miss handling of the loser in a race, are the keys to implementing snooping cache coherence without a bus. We explain the details in Appendix I.
- Possible to combine snooping and directories
- several designs use snooping within a multicore and directories among multiple chips
- A combination of directories at one cache level and snooping at another level
Performance of Symmetric Shared-Memory Multiprocessors
Overall cache performance is a combination of the behavior of:
- Uniprocessor cache miss traffic by cache miss rate
- Capacity
- Compulsory
- Conflict
- traffic caused by coherence miss rate
-
True sharing misses
- The first write by a processor to a shared cache block causes an invalidation to establish ownership of that block
-
False sharing
- Occurs when a block is invalidated (and a subsequent reference causes a miss) because some word in the block, other than the one being read, is written into.
- The block is shared, but no word in the cache is actually shared
-
Block size?
- The miss would not occur if the block size were a single word
-
True sharing misses
- Example of False sharing
- Words
z1andz2are in the same cache block - The block is shared by
P1andP2processors
- Words

Will upload workload analysis subsections such as …
- A Commercial Workload
- A Multiprogramming and OS Workload
- Performance of the Multiprogramming and OS Workload
Distributed Shared-Memory and Directory-Based Coherence
The absence of any centralized data structure that tracks the state of the caches is both the fundamental advantage of a snooping-based scheme, since it allows it to be inexpensive, as well as its Achilles’ heel when it comes to scalability.
Directory protocol:
- Keeps the state of every block that may be cached
- Information in the directory includes
- which caches (or collections of caches) have copies of the block,
- whether it is dirty, and so on.
-
Single directory within a multicore with a shared outermost cache
- Say, L3
- Easy to implement a directory scheme
- Simply keep a bit vector of the size equal to the number of cores for each L3 block
-
No broadcast
- Invalidations are sent only to the caches that shares the same cache blocks
- Still, not scalable!!
- Even though it avoids broadcast
-
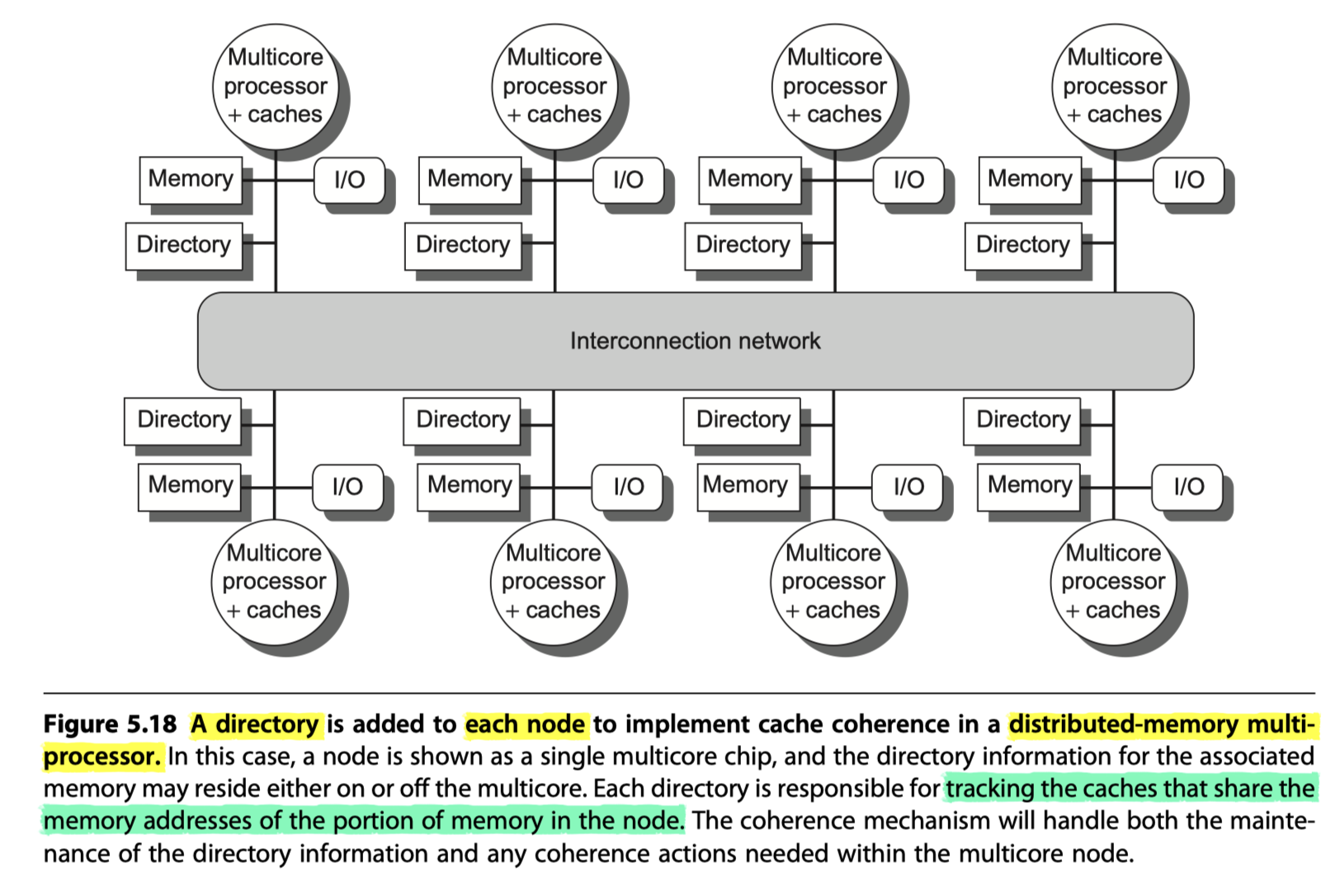
Distributed directory
- Must know where to find the directory information for any cached block of memory
- Distribute the directory along with the memory so that different coherence requests can go to different directories, just as different memory requests go to different memories.
-
Avoid broadcast!
- The sharing status of a block is stored in a single known location
- Directory in a shared outer cache (L3)?
- Distribute the directory information to different cache banks!
- Simplest implementation?
- Associate an entry in the directory with each memory block
- Node can be
- a single multiprocessor
- a small collection of processors that implements coherence internally
- #information $\propto$ #(memory blocks)$\times$#nodes
Directory-Based Cache Coherence Protocols: The Basics
Two primary operation that a directory protocol must implement:
- (1) Handling a read miss and
- (2) Handling a write to a shared, clean cache block.
- (1+2) Handling a write miss to a block that is currently shared is a simple combination of these two.
State of each cache block:
- Shared — One or more nodes have the block cached, and the value in memory is up to date (as well as in all the caches)
- Uncached — No node has a copy of the cache block.
- Modified — Exactly one node has a copy of the cache block, and it has written the block, so the memory copy is out of date. The processor is called the owner of the block
Must track:
- the state of each potentially shared memory block and
- which nodes have copies of that block because those copies will need to be invalidated on a write
Implemented by keeping a bit vector for each memory block:
- Each bit of the vector indicates whether the corresponding processor chip (which is likely a multicore) has a copy of that block
- + Keep track of the owner of the block when the block is in the exclusive state
-
- For efficiency reasons, we also track the state of each cache block at the individual caches
A catalog of the message types that may be sent between the processors and the directories for the purpose of handling misses and maintaining coherence
- Local node $-$ the node where a request originates.
-
Home node $-$ the node where the memory location and the directory entry of an address reside
- The location of the home node is known for a given physical address
- Remote node $-$ the node that has a copy of a cache block, whether exclusive (in which case it is the only copy) or shared
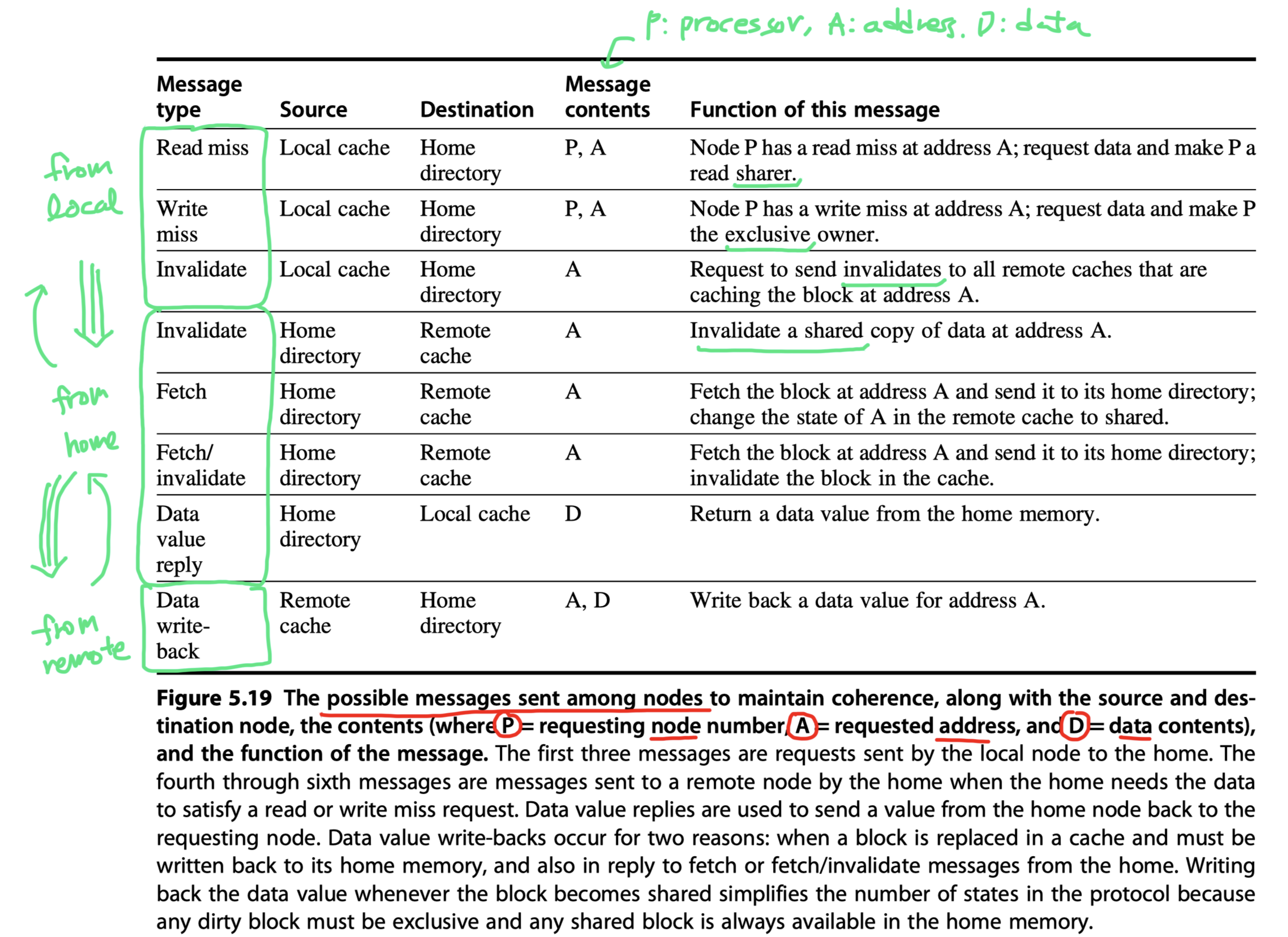
In this section, we assume a simple model of memory consistency.
- Messages will be
- Received and acted upon in the same order they are sent.
- To minimize the type of messages and the complexity of the protocol,
- Ensure that invalidates sent by a node are honored before new messages are transmitted
- Not true in practice, See Section 5.6
An Example Directory Protocol
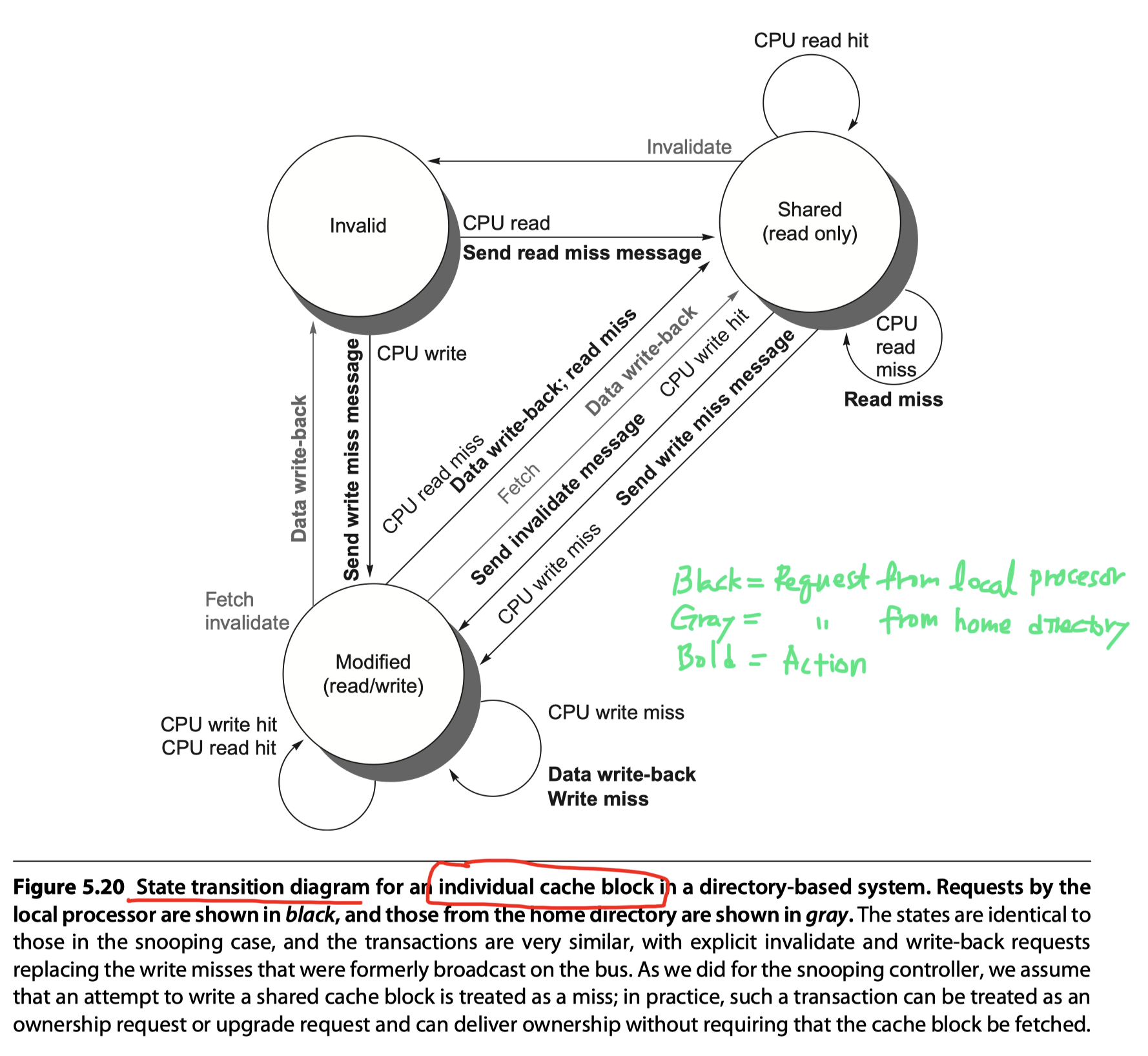
(The 1st half implementation of the directory-based coherence) State transition diagram for an individual cache block: (Gray = Requests coming from outside the node, Bold = Actions)
- Almost identical with snooping case
- Write miss operation
- Snooping-based $\rightarrow$ Broadcast
- Directory-based $\rightarrow$ Data fetch and invalidate
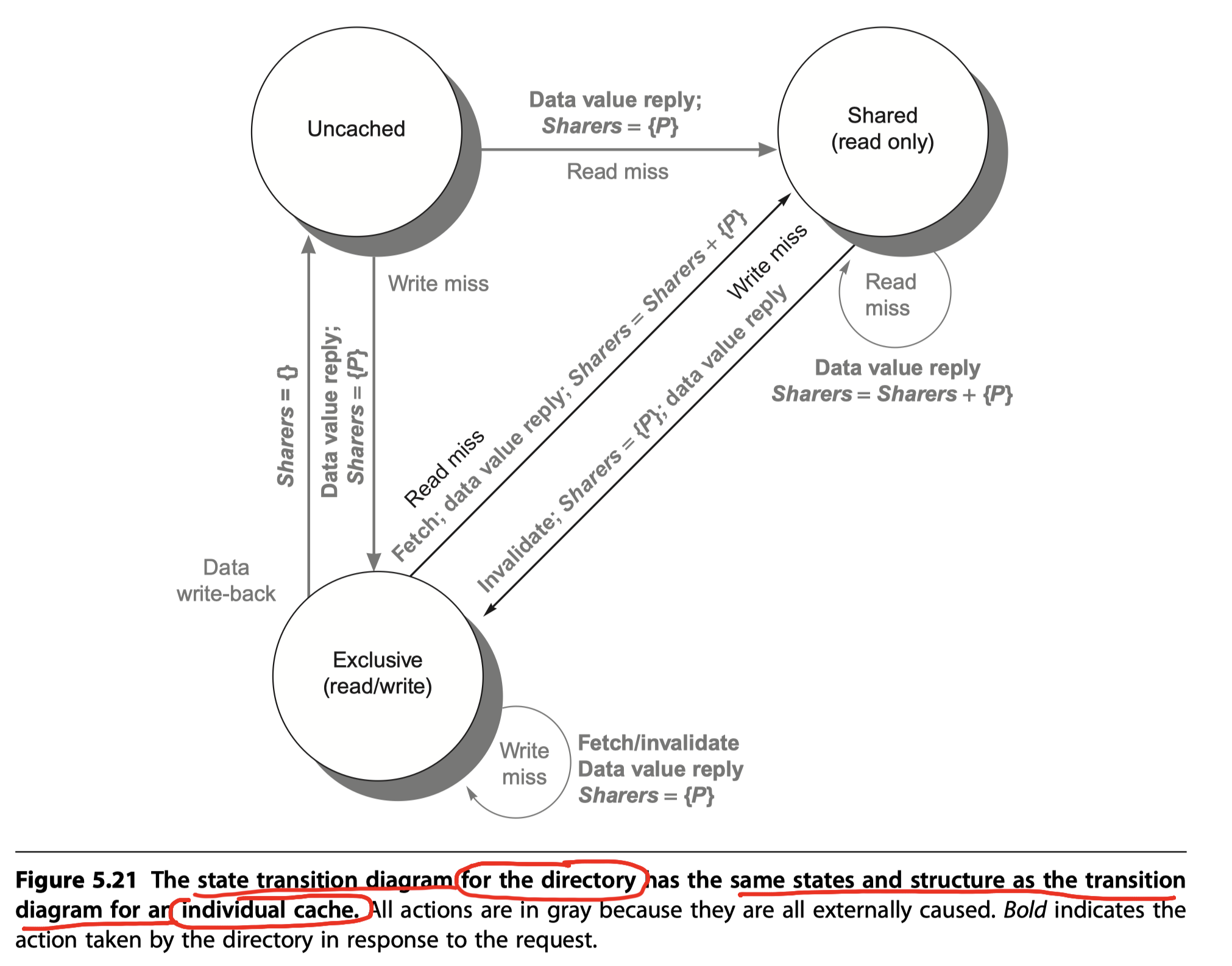
(The 2nd half implementation of the directory-based coherence) State transition diagram for the directory:
- A message sent to a directory causes two different types of actions
- Updating the directory state and
- Sending additional messages to satisfy the request
-
Directory states:
- Unlike in a snooping scheme, however, the directory state indicates the state of all the cached copies of a memory block, rather than for a single cache block.
- Memory block may be
- Uncached by any node,
- Cached in multiple nodes and readable (shared), or
- Cached exclusively and writable in exactly one node
-
Sharers
- A set to perform a function that tracks the set of nodes that have a copy of a block
- A directory receives three different requests
-
Read miss
- Uncached $\rightarrow$ Shared
- The requesting node is sent the requested data from memory and become the only sharing node
- Shared $\rightarrow$ Shared
- The requesting node is sent the requested data from memory and become a sharing node
- Exclusive $\rightarrow$ Shared
- The owner is sent a data fetch message, send data to the directory (in memory), and become sharing node
- The requesting node is sent the requested data from the memory and become a sharing node
- Uncached $\rightarrow$ Shared
-
Write miss
- Uncached $\rightarrow$ Exclusive
- The requesting node is sent the value and become the only sharing node
- Shared $\rightarrow$ Exclusive
- The requesting node is sent the value and become the only sharing node
- All nodes in the set Sharers are sent invalidate messages
- Exclusive $\rightarrow$ Exclusive
- The block has a new owner
- The old owner is invalidated, send the value to the directory, and finally to the requesting node
- Maybe optimized by directly forwarding the value from the old owner to the new owner
- Uncached $\rightarrow$ Exclusive
-
Data write-back
- Exclusive $\rightarrow$ Uncached
- The owner is replacing the block and therefore must write it back.
- Exclusive $\rightarrow$ Uncached
-
Read miss
Note: All actions are assume to be atomic, which is not true in reality. Check Appendix I that explore non-atomic memory transactions
Additional optimization?
- Write-miss to an exclusive block:
- Many of the protocols in use in commercial multiprocessors forward the data from the owner node to the requesting node directly (as well as performing the write-back to the home).
- Side effect:
- Add complexity by increasing the possibility of deadlock and by increasing the types of messages
Synchronization: The Basics
Synchronization mechanisms
- Built with user-level software routines that
- Rely on hardware-supplied synchronization instructions
- Key hardware capability?
- an uninterruptible instruction or
- instruction sequence capable of atomically retrieving and changing a value
In this section, we focus on the implementation of lock and unlock synchronization operations $\rightarrow$ Create mutual exclusion and more complex synchronization mechanisms
In high-contention situations, synchronization can become a performance bottleneck because contention introduces additional delays and because latency is potentially greater in such a multiprocessor $\rightarrow$ See Appendix I
Basic Hardware Primitives
Need to implement a set of hardware primitives with the ability to
- Atomically read and
- Modify a memory location
$\rightarrow$ Basic building block for
- Building a wide variety of user-level synchronization operations,
- Including things such as locks and barriers
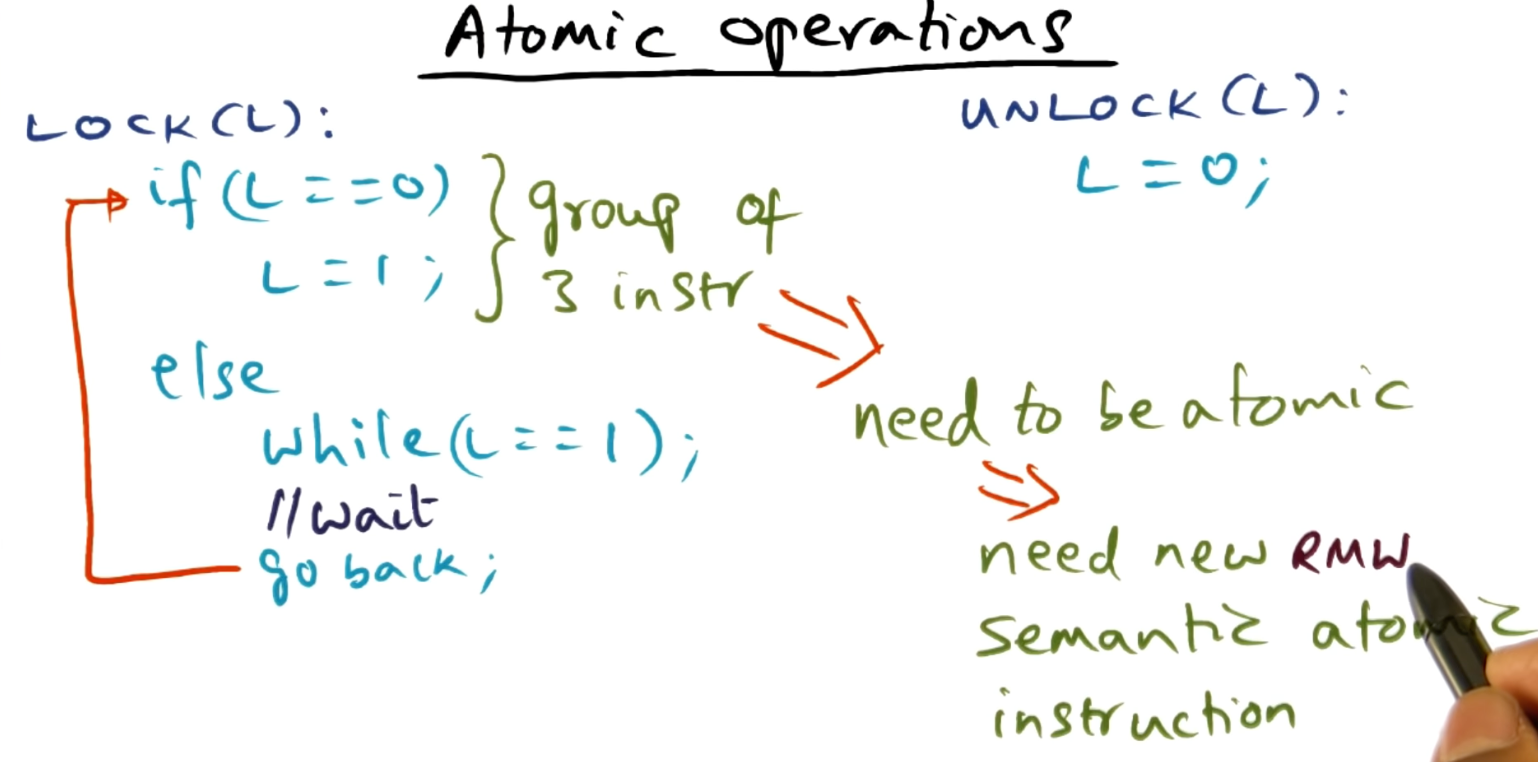
Atomic exchange:
- Interchanges a value in a register for a value in memory
- Want to build a simple lock
- The value 0 is used to indicate that the lock is free and
- 1 is used to indicate that the lock is unavailable
- A processor tries to set the lock by doing an exchange of 1,
- which is in a register,
- with the memory address corresponding to the lock
- Then, the value returned from the exchange instruction is
- 1 if some other processor had already claimed access and
- 0 otherwise (unlocked)
- $\rightarrow$ The value is changed to 1 then,
- Preventing any competing exchange from also retrieving a 0
- Example
- Two processors are trying to do the exchange simultaneously
- Only one processor can be a winner in this race
- Want to build a simple lock
Atomicity of atomic exchange operation?
- The exchange is indivisible
- Two simultaneous exchanges will be ordered by the write serialization mechanisms.
Lock and unlock - Georgia Tech - Advanced Operating Systems
Atomic synchronization primitives:
- Test-and-set
- Tests a value (if it is 0)
- Sets (to 1) it if the value passes the test
- Fetch-and-increment
- Returns the value of a memory location and
- Atomically increments it.
Atomic Read-Modify-Write instructions - Georgia Tech - Advanced Operating Systems

Challenges to implement a single atomic memory operation:
- Require both a memory read and a write
- In a single, uninterruptible instruction
- This requirement complicates the implementation of coherence
- Because the hardware cannot allow any other operations
- Between the read and the write, and
- Yet must not deadlock.
Alternative approach used in MIPS and RISC-V:
- Have a pair of instructions
- where the second instruction returns a value
- from which it can be deduced whether the pair of instructions was executed as though the instructions were atomic
- The pair of instructions is effectively atomic if
- it appears as though all other operations executed by any processor occurred before or after the pair
The pair of instructions in RISC-V:
-
load reserved (also called load linked or load locked)
- loads the contents of memory given by rs1 into rd and creates a reservation on that memory address
-
store conditional
- Stores the value in rs2 into the memory address given by rs1
-
How does it work?
- If the reservation of the load is broken by a write to the same memory location
- The store conditional fails and writes a nonzero to rd;
- If it succeeds, the store conditional writes 0
- If the processor does context switch between the two $\rightarrow$ SC always fails
- If the reservation of the load is broken by a write to the same memory location
- Example
- An atomic exchange on the memory location specified by the contents of
x1with the value inx4 - At the end of this sequence, the contents of
x4and the memory location specified byx1have been atomically exchanged.
- An atomic exchange on the memory location specified by the contents of
An advantage of the load reserved/store conditional mechanism?
- You can build other synchronization primitives
- Example: an atomic fetch-and-increment

How to implement lr/sc instructions?
- Keep track of the address specified in the
lrinstruction in a register- Called the reserved register
- If an interrupt occurs, or if the cache block matching the address in the link register is invalidated (e.g., by another
sc), - The link register is cleared.
- The
scinstruction simply checks that its address matches that in the reserved register.- If so, the sc succeeds;
- Otherwise, it fails.
Deadlock cases?
- Because the store conditional will fail after either another attempted store to the load reserved address or any exception,
- Care must be taken in choosing what instructions are inserted between the two instructions.
- In particular, only register-register instructions can safely be permitted;
- Otherwise, it is possible to create deadlock situations
- where the processor can never complete the
sc.
- where the processor can never complete the
- In addition, the number of instructions between the load reserved and the store conditional should be small to minimize the probability that either an unrelated event or a competing processor causes the store conditional to fail frequently.
Synchronization Examples in RISC-V by Amir H. Ashouri
- Based on “Computer Organization and Design RISC-V Edition- The Hardware Software Interface” by David Patterson and John Hennessy


cf. How does a barrier work?
- From Centralized barrier - Georgia Tech - Advanced Operating Systems
- Two spinning episodes:
- (1)
while ( count > 0 ); - (2)
while ( count != n );
- (1)
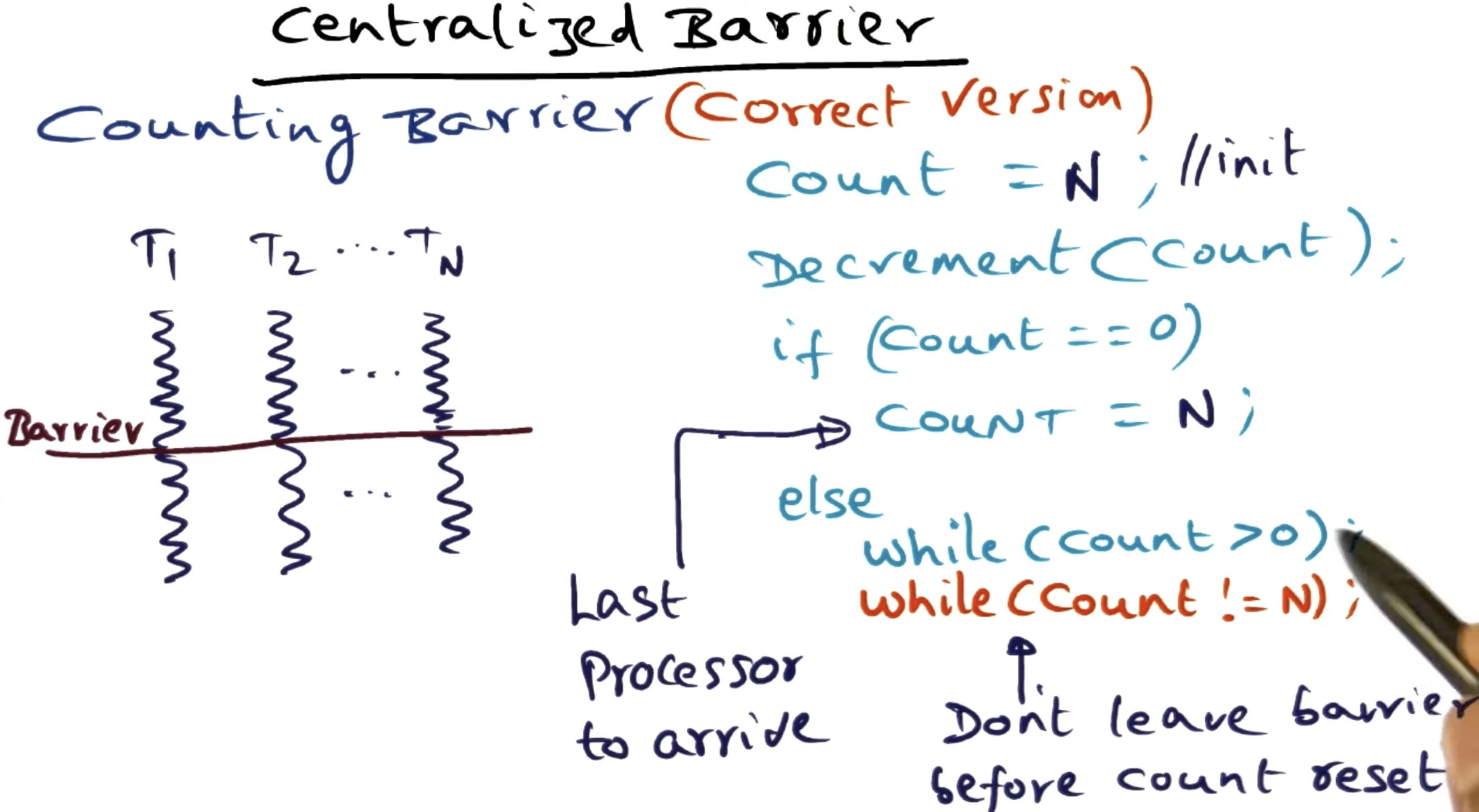
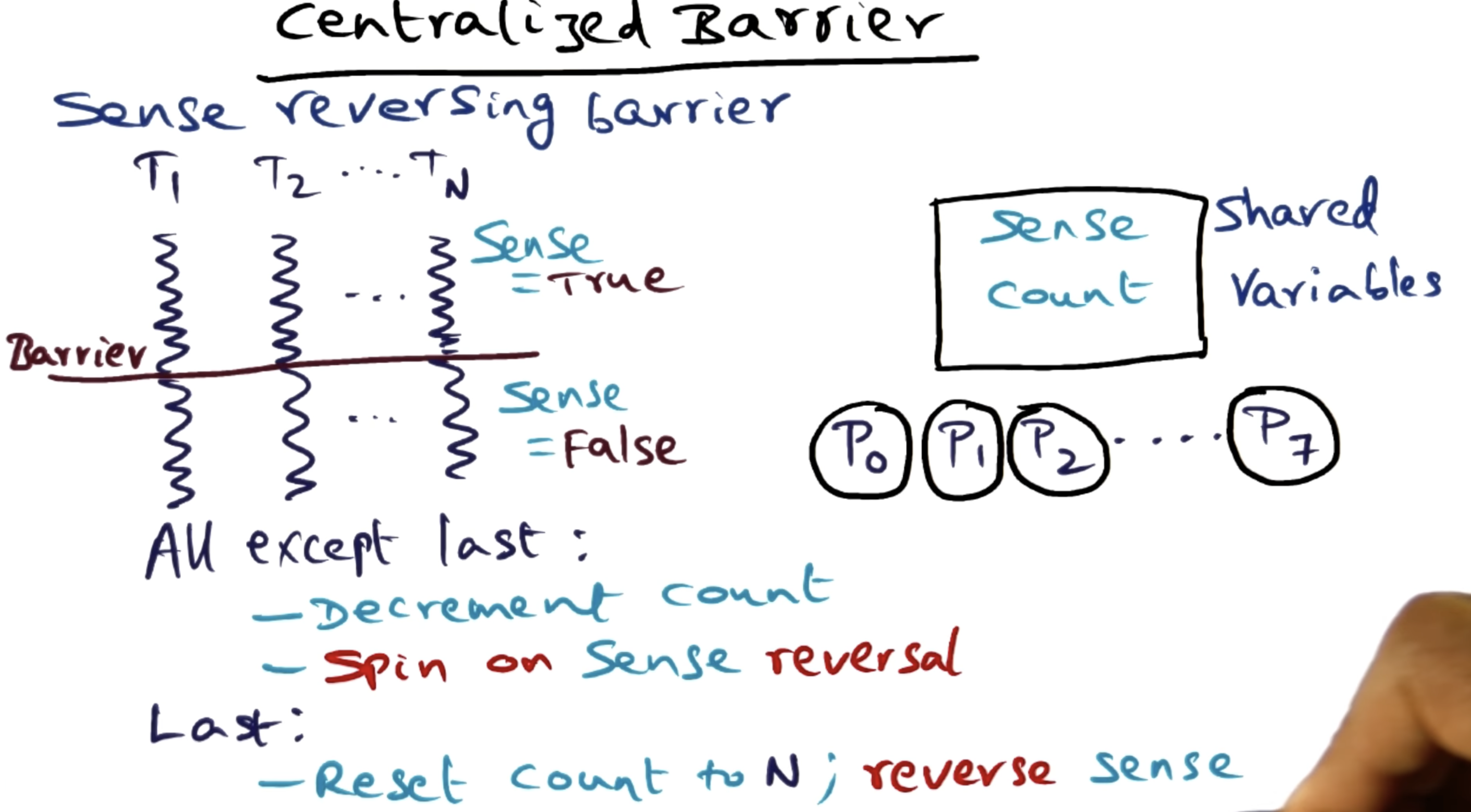
- From Barrier Synchronization - Georgia Tech - HPCA: Part 5
- In this Part5 playlist and Part6 playlist
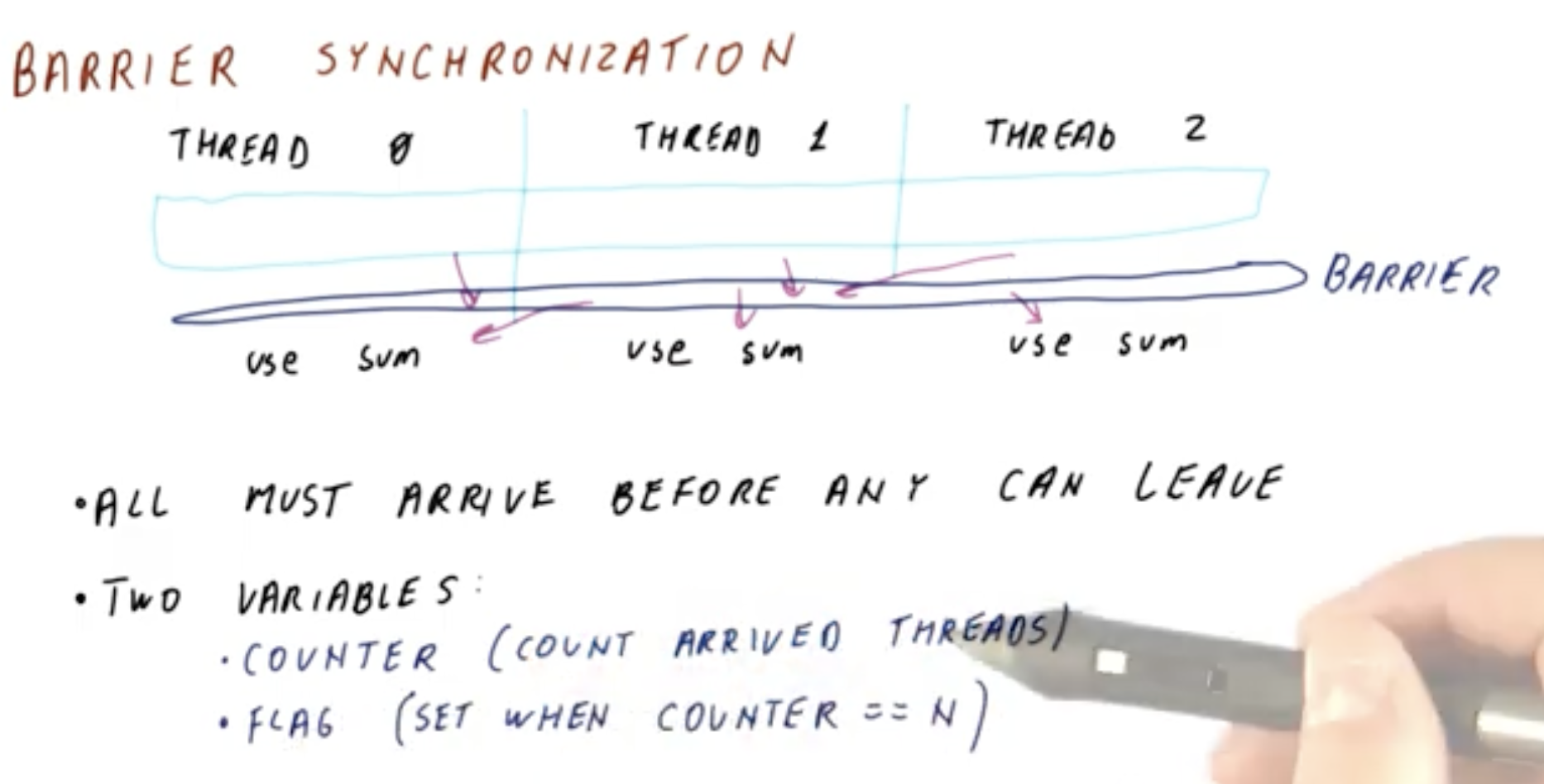

- In this Part5 playlist and Part6 playlist

Implementing Locks Using Coherence
Using atomic operation $\rightarrow$ Use coherence mechanisms of a multiprocessors to implement spin locks:
- Spin locks
- Locks that a processor continuously tries to acquire, spinning around a loop until it succeeds
- Spin locks tie up the processor waiting in a loop for the lock to become free
Simplest implementation without cache coherence
- Keep the lock variables in memory (not in a private cache)
- A processor could continually try to acquire the lock
- Using an atomic operation, say, atomic exchange, and
- Test whether the exchange returned the lock as free
- Spin locks are used
- when programmers expect the lock to be held for a very short amount of time and
- when they want the process of locking to be low latency when the lock is available
- Code sequence to lock a spin lock
-
EXCH: A macro for the atomic exchange sequence above usinglr/scinstructions
-

With cache coherence?
- We can cache the locks using the coherence mechanism to maintain the lock value coherently
-
Advantage of caching locks
- The process of “spinning” could be done on a local cached copy
- There is often locality in lock accesses
- i.e. The processor that used the lock last will use it again in the near future.
- $\rightarrow$ Greatly reducing the time to acquire the lock.
- Change in the simple spin procedure: Read before exchange!
- Motivation
- Each attempt to exchange in the preceding loop requires a write operation.
- If multiple processors are attempting to get the lock, each will generate the write.
- $\rightarrow$ Most of these writes will lead to write misses because each processor is trying to obtain the lock variable in an exclusive state.
- Thus we should modify our spin lock procedure so that
- It spins by doing reads on a local copy of the lock until it successfully sees that the lock is available
- Then it attempts to acquire the lock by doing a swap operation.
- Motivation

Figure 5.22 examines how this “spin lock” scheme uses the cache coherence mechanisms:
- This example shows another advantage of the load reserved/store conditional primitives:
- The read and write operations are explicitly separated.
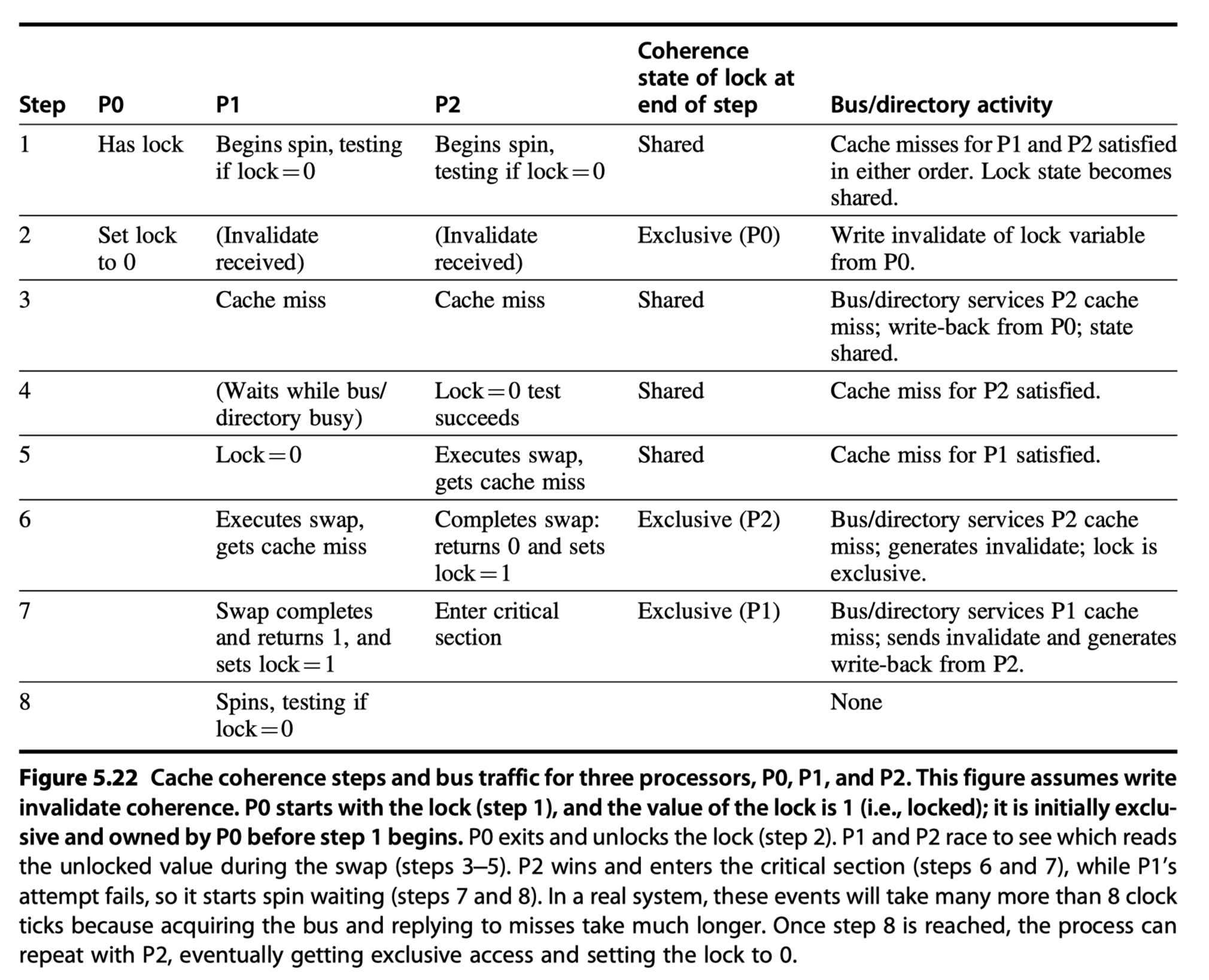
The fact that the load reserved need not cause any bus traffic
- Allows the following simple code sequence,
- which has the same characteristics as the optimized version using exchange
- (
x1has the address of the lock, thelrhas replaced theLD, and theschas replaced theEXCH)
- The first branch forms the spinning loop
- The second branch resolves races when two processors see the lock availability simultaneously

Models of Memory Consistency: An Introduction
Cache coherence
- Ensures that multiple processors see a consistent view of memory.
- Does not answer the question of how consistent the view of memory must be.
- Q: When must a processor see a value that has been updated by another processor?
- = In what order must a processor observe the data writes of another processor?
- = What properties must be enforced among reads and writes to different locations by different processors?
- In this slide, programmer never expect the fourth case (R1=1,R2=0),
- But, it can happen without memory consistency
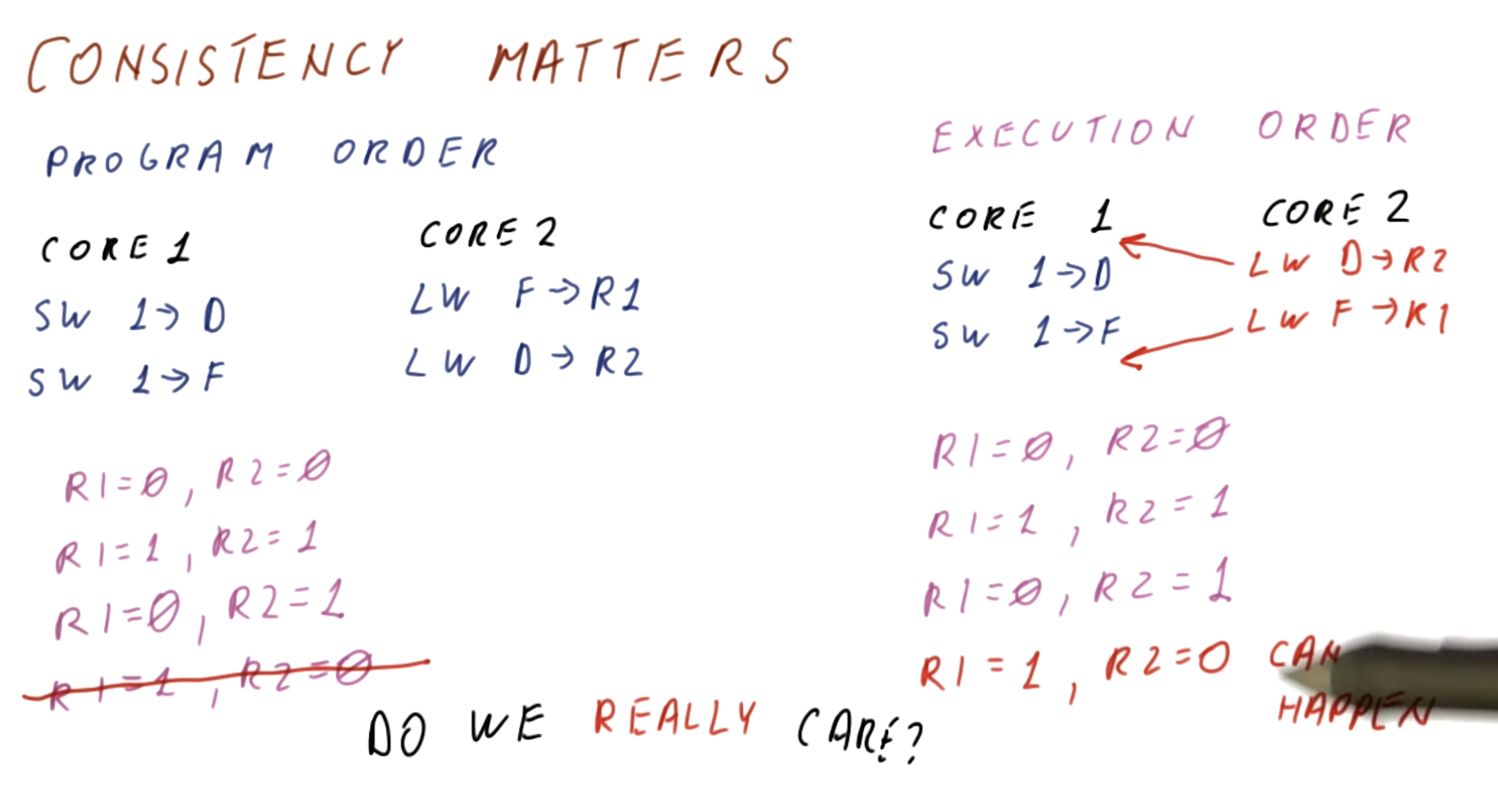
Look at this two code segments from processes P1 and P2
- The processes are running in different processors
- A and B are originally cached by both processors with initial value of 0
- A=0, B=0 in the cache of P1
- A=0, B=0 in the cache of P2
- Writes take immediate effects?
- Impossible for both L1 and L2 to be true
- If write invalidate is delayed (by interconnect latency or something else)
- Possible that both P1 and P2 have not seen the invalidations $\rightarrow$ L1/L2 can be false!
-
Is it allowed? in what condition?

Sequential Consistency
- Requires that the result of any execution be the same as though
- The memory accesses executed by each processor were kept in order
- The accesses among different processors were arbitrarily interleaved
- Eliminates the possibility of some nonobvious execution in the previous example because the assignments must be completed before the IF statements are initiated.
-
Simplest implementation?
- Require a processor to delay the completion of any memory access until all the invalidation caused by that access are completed.
- Example
- Write miss = 50 cycles to establish ownership,
- 10 cycles to issue each invalidate after ownership is established
- 80 cycles for an invalidate to complete and be acknowledged once it is issued
- Four other processors share a cache block
- Q: How long does a write miss stall the writing processor if the processor is sequentially consistent?
- A: The last processor’s invalidation starts 10+10+10+10= 40 cycles after ownership is established. $\rightarrow$ Total time = 50 (ownship) + 40 (issue) + 80 (invalidata/acknowledge) = 170 cycles
The Programmer’s View
Although the sequential consistency model has a performance disadvantage, from the viewpoint of the programmer, it has the advantage of simplicity
- Challenge
- Develop a programming model that is
- Simple to explain and
- Yet allows a high-performance implementation.
Synchronized programs
- More efficient implementation
- All accesses to shared data are ordered by synchronization operations
- Data-race-free
- Data-race: The execution outcome depends on the relative speed of the processors
- Example
- Two processors share a data
- Each processors surrounds the read and update with a lock and an unlock,
- Both to ensure mutual exclusion for the update and to ensure that the read is consistent
- Almost all programmers will choose to use synchronization libraries that are correct and optimized for the multiprocessor and the type of synchronization.
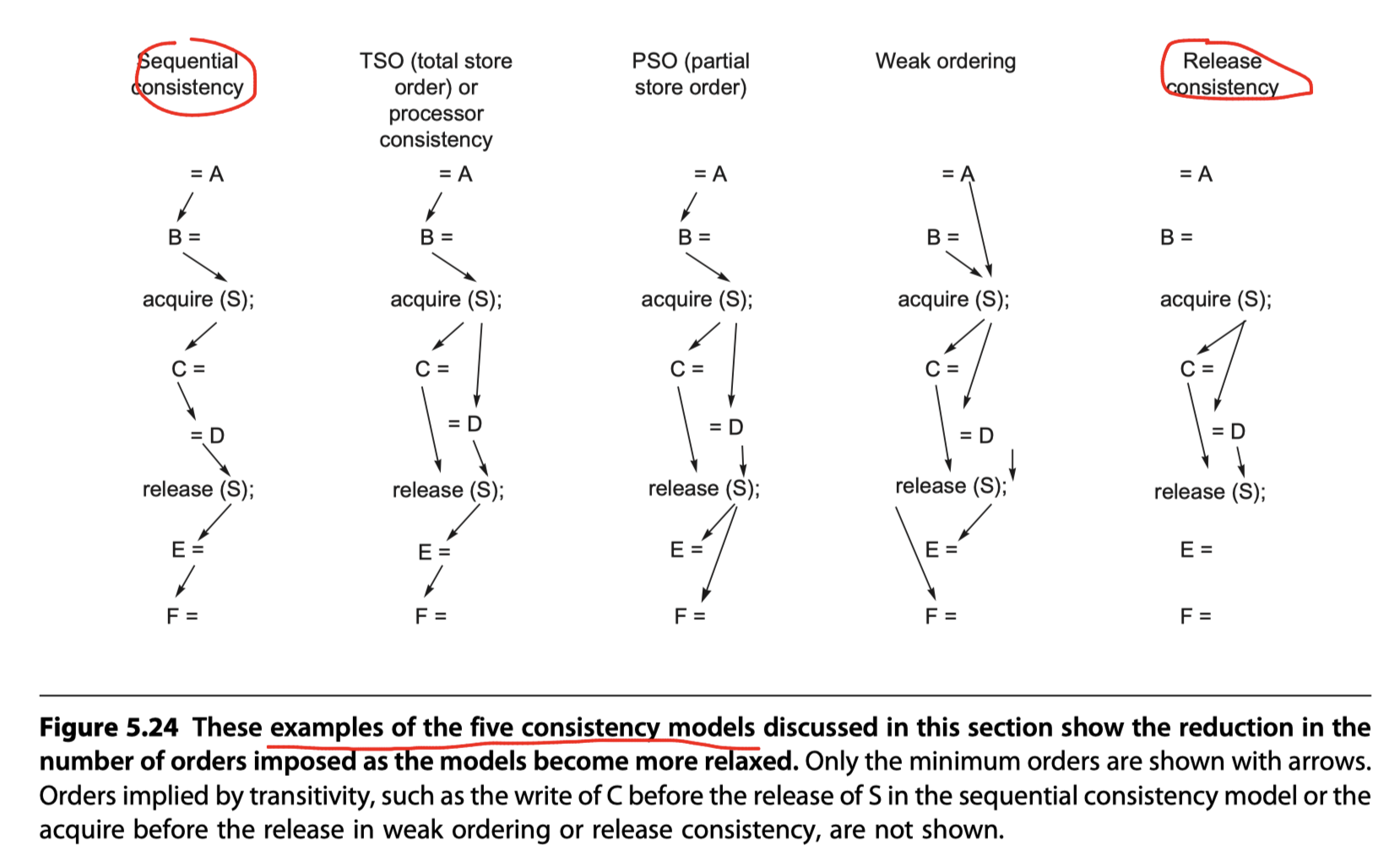
Relaxed Consistency Models: The Basics and Release Consistency
Relaxed consistency model:
- Allow reads and writes to complete out of order
- But to use synchronization operations to enforce ordering so that
- A synchronized program behaves as though the processors were sequentially consistent
Sequential consistency requires maintaining all four possible orderings:
- R $\rightarrow$ W
- R $\rightarrow$ R
- W $\rightarrow$ R
- W $\rightarrow$ W
- where X $\rightarrow$ Y means that operation X must complete before operation Y is done
Relaxed model categories:
-
Total store ordering or processor consistency
- Relaxing only the W$\rightarrow$ R ordering
- Partial store order
- Relaxing both W$\rightarrow$R ordering and W$\rightarrow$W ordering
- Weak ordering, the PowerPC consistency model, and release consistency
- Relaxing all four ordering
- Significant performance advantage
- RISC V, ARMv8, as well as the C++ and C language standards chose release consistency as the model
Release consistency distinguishes between
- Synchronization operations that are used to acquire access to a shared variable ($S_A$) and
- Those that release an object to allow another processor to acquire access (denoted $S_R$).
This property allows us to slightly relax the ordering by
- (1) Observing that a read or write that precedes an acquire need not complete before the acquire, and also that
- (2) A read or write that follows a release need not wait for the release.

Cross-Cutting Issues
Compiler Optimization and the Consistency Model
In explicitly parallel program without clear synchronization point definition,
- The compiler cannot interchange a read and a write of two different shared data items
- Restricts simple optimizations like register allocation of shared data
In implicitly parallelized programs,
- Programs must be synced and the sync points are known
- So, more room for compiler to optimize
Using Speculation to Hide Latency in Strict Consistency Models
Use dynamic scheduling to reorder memory references,
- letting them possibly execute out of order.
Delayed commit feature of a speculative processor
- Avoid the violations of sequential consistency for out of order memory references
- Eg. Memory reference execution (Not committed yet) $\rightarrow$ Receive invalidation $\rightarrow$ Speculation recovery $\rightarrow$ Restart the memory reference
So, need to detect when the results might differ by the reordering of memory requests
- Triggered only when there are unsynchronized accesses that actually cause a race (Gharachorloo et al., 1992).
The combination of sequential or processor consistency together with speculative execution as the consistency model of choice (Hill (1998)) Why?
- Aggressive implementation of sequential consistency $\ni$ Advantage of a more relaxed model
- Very little implementation cost of a speculative processor
- Allows the programmer to use the simpler programming models
Inclusion and Its Implementation
Multi-level inclusion of cache?
- Every level of cache hierarchy is a subset of the level farther away from the processor
- Can reduce the contention
- between coherence traffic and processor traffic that
- occurs when snoops and processor cache accesses must contend for the cache
Two-level example
- If different block sizes for L1 and L2
- L2 cache miss can break the inclusion property
- How to maintain inclusion with multiple block sizes?
- Must probe the higher levels of the hierarchy when a replacement is done at the lower level
- Or, just use one block size for all memory hierarchy
Performance Gains From Multiprocessing and Multithreading
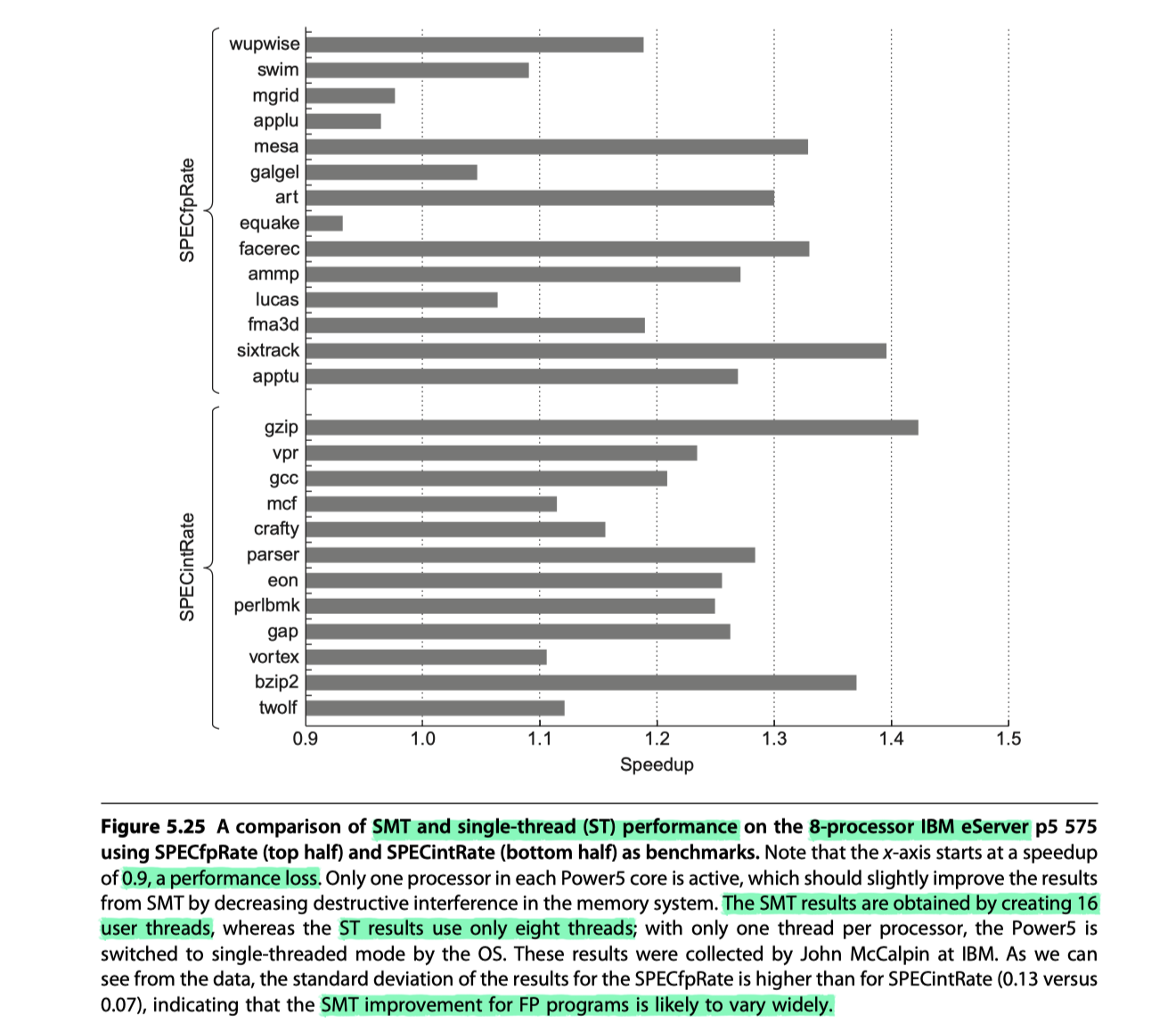
IBM Power5
- Dual core with simultaneous multithreading (SMT)
- Average
- SPECintRate2000 $\rightarrow$ 1.23x
- SPECfpRate $\rightarrow$ 1.16x
Putting It All Together: Multicore Processors and Their Performance
Performance of Multicore-Based Multiprocessors on a Multiprogrammed Workload
Three different multicore
- Xeon systems
- i7 920
- i7 6700
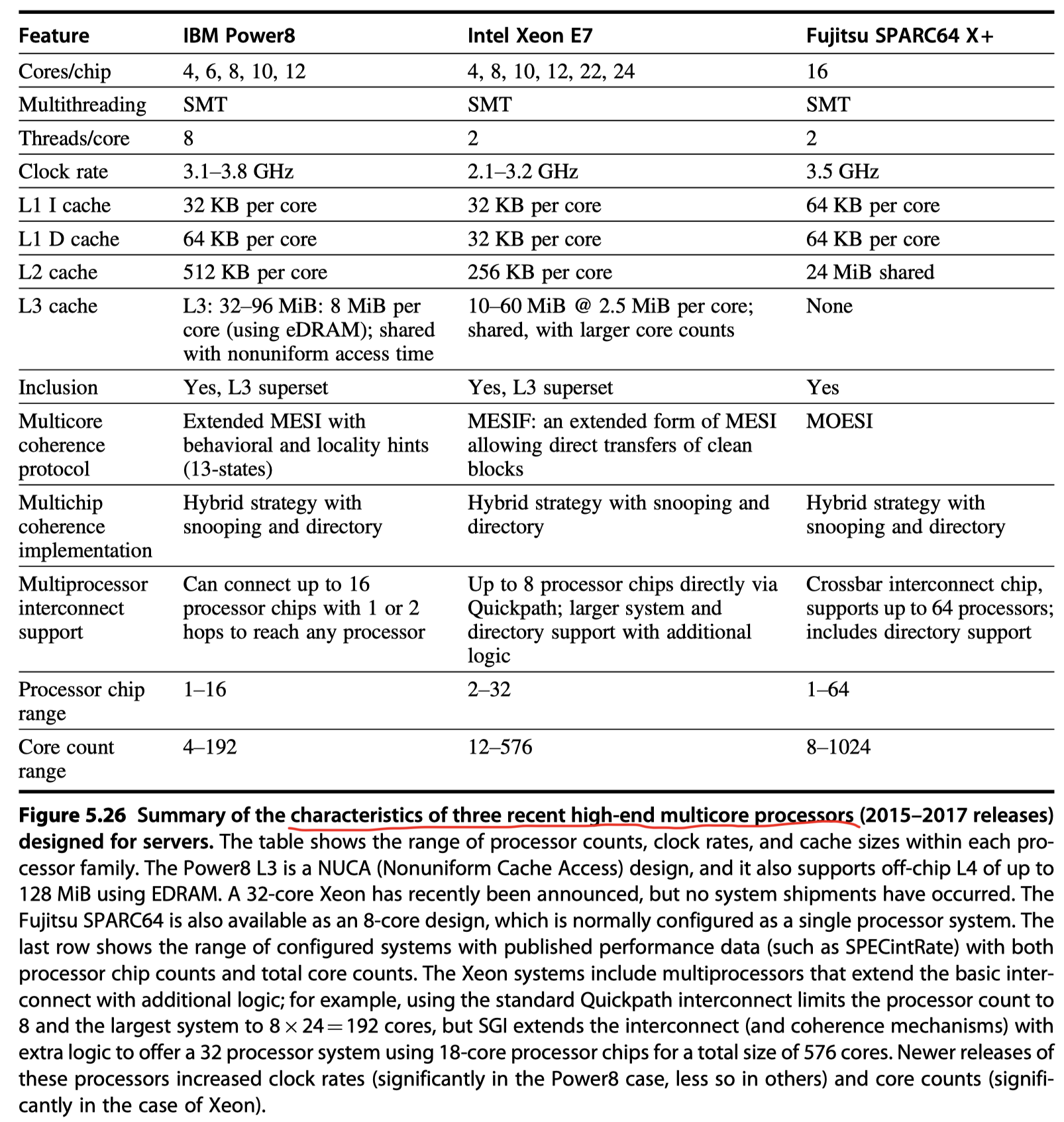
Figure 5.26 : Key characteristics of three multicore processsors
- Intel Xeon E7
- Based on i7, more cores, a slightly slower clock rate, larger L3
- IBM Power8
- New IBM Power series with more cores and bigger caches
- Fujitsu SPARC64 X+
- Server chip with SMT
How the cores are connected within a chip
-
SPARC64 X+
- The simplest
- 16 cores share a single L2 cache
- 24-way set associative
- Four separate DIMM channels,
- 16 $\times$ 4 switch between 16 cores and 4 DIMM channels
-
Power8
- Each core has an 8 MiB bank of L3 directly connected
- Other banks accessed via the interconnection network with 8 separate buses
- So, it’s a true NUCA (Nonuniform Cache Architecture)
- Memory links $\leftrightarrow$ Special memory controller with L4 and interfaces directly with DIMMs
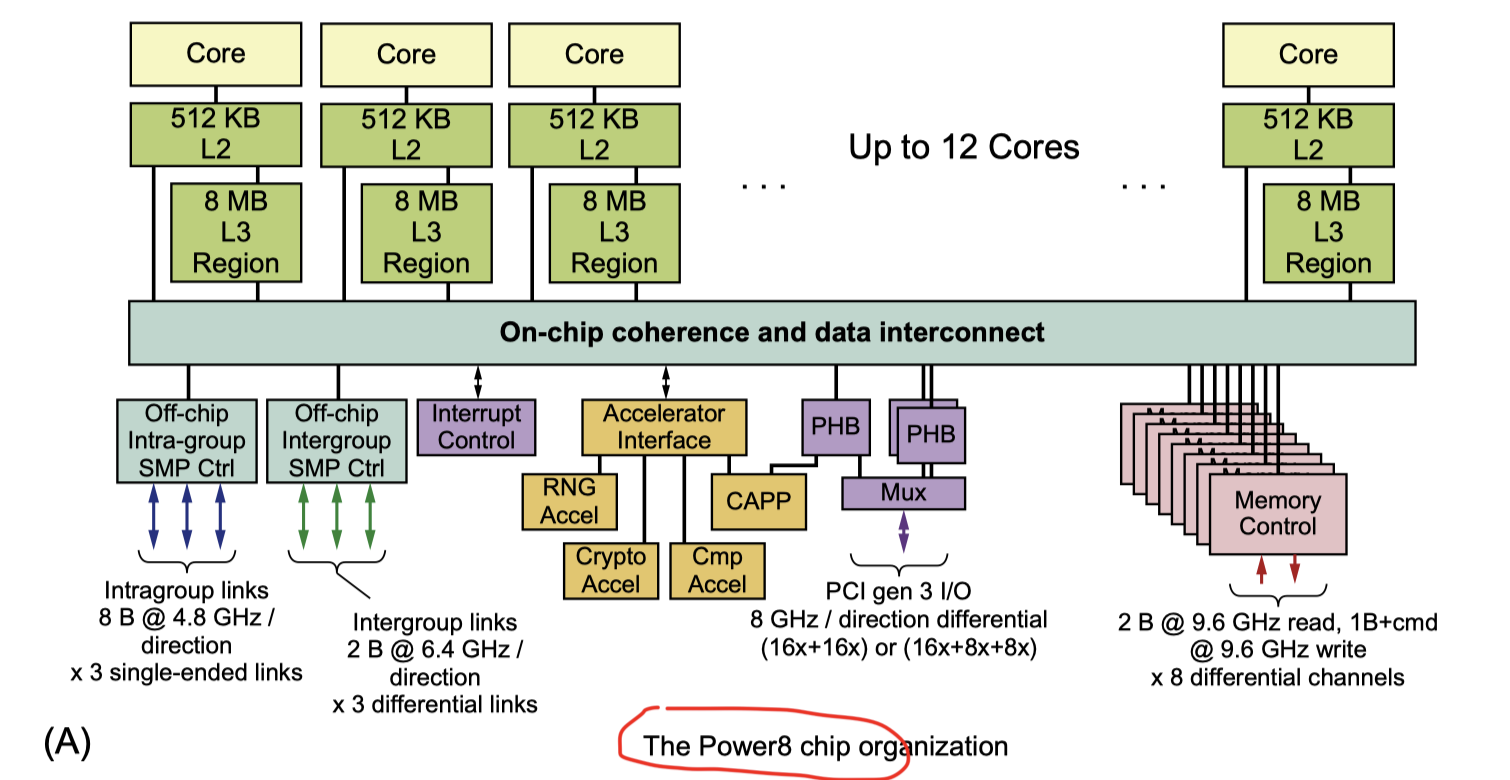
-
Xeon E7
- 18 or more cores (20s in Figure5.27(b))
- Three rings!!
- Connect the cores and the L3 cache banks
- Each core and each bank of L3 $\leftrightarrow$ Two rings
- Uniform access time within a chip
- Normally operated as a NUMA architecture
- By logically half the cores with each memory channel
- $\rightarrow$ Increases the probability that a desired memory page is open on a given access
- Connecting multiple E7s: Three QuickPath Interconnect (QPI)
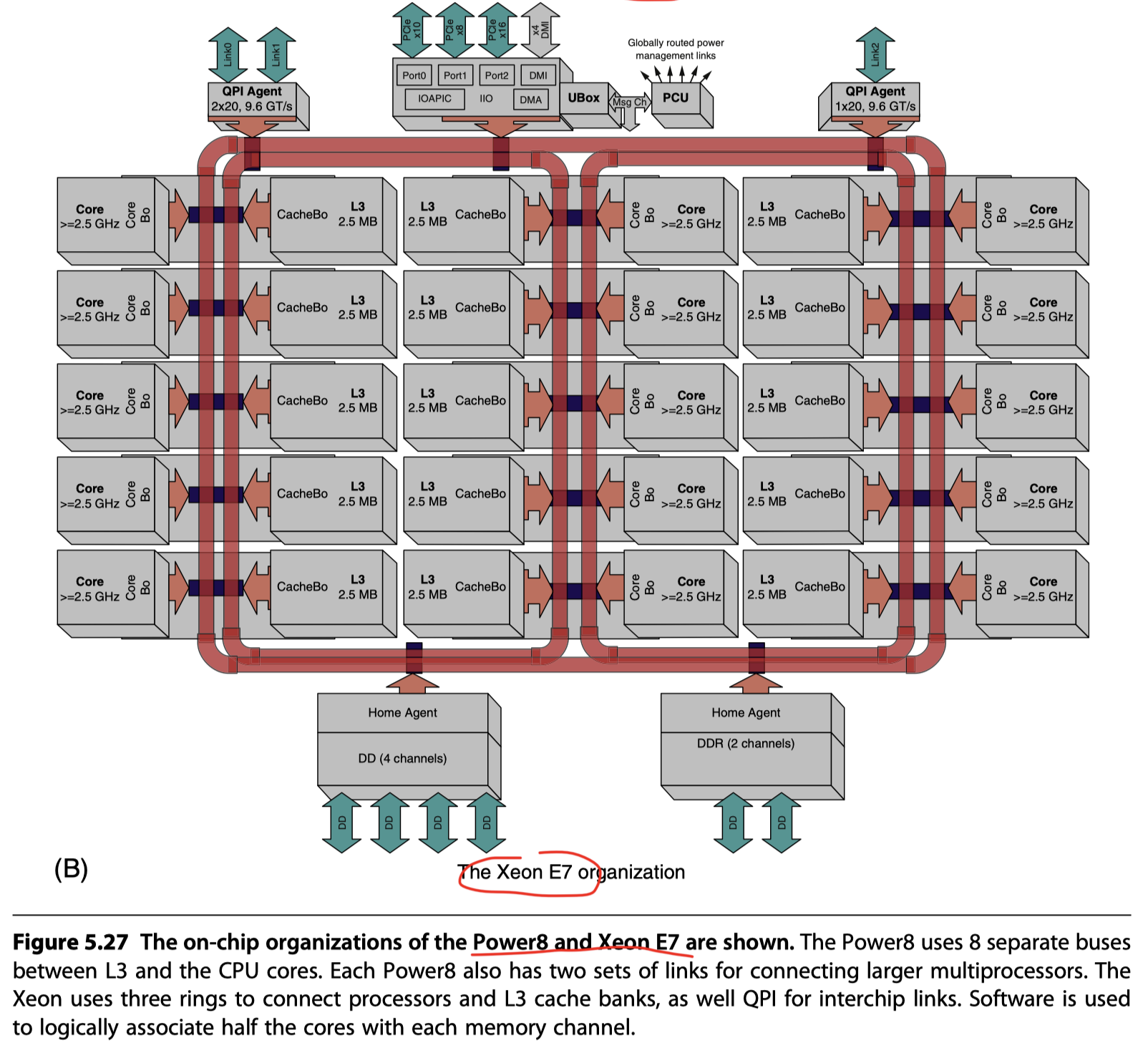
Different interconnection strategies
-
IBM Power8
- Connecting 16 Power8 chips for a total of 192 cores
- Intra-group links for 4 processor chips
- Each processor is two hops from any other
- Different memory access time
- (1) local memory, (2) cluster memory, (3) inter-cluster memory
-
Intel Xeon E7
- Chip $\leftrightarrow$ QPI $\leftrightarrow$ Chip
- 3 QPI links for 4-chip multiprocessor with 128 cores
- 8 E7 processors
- One or two hops
- More than 8 chips?
- 4 chips as a module
- Each processor is connected to two neighbors (Two QPIs)
- Third QPI $\rightarrow$ A crossbar witch
- Different memory access time
- (1) Local to the processors
- (2) An immediate neighbor
- (3) The neighbor in the cluster that is two hops away
- (4) Through the crossbar
-
SPARC64 X+
- Each processor
- Three connections to its immediate neighbors
-
- Two/three connections to a crossbar
- 64 processors $\rightarrow$ Two crossbar switches
- Different memory access time (NUMA)
- (1) local, (2) within a module, and (3) through the crossbar
- Directory based coherency
- Each processor
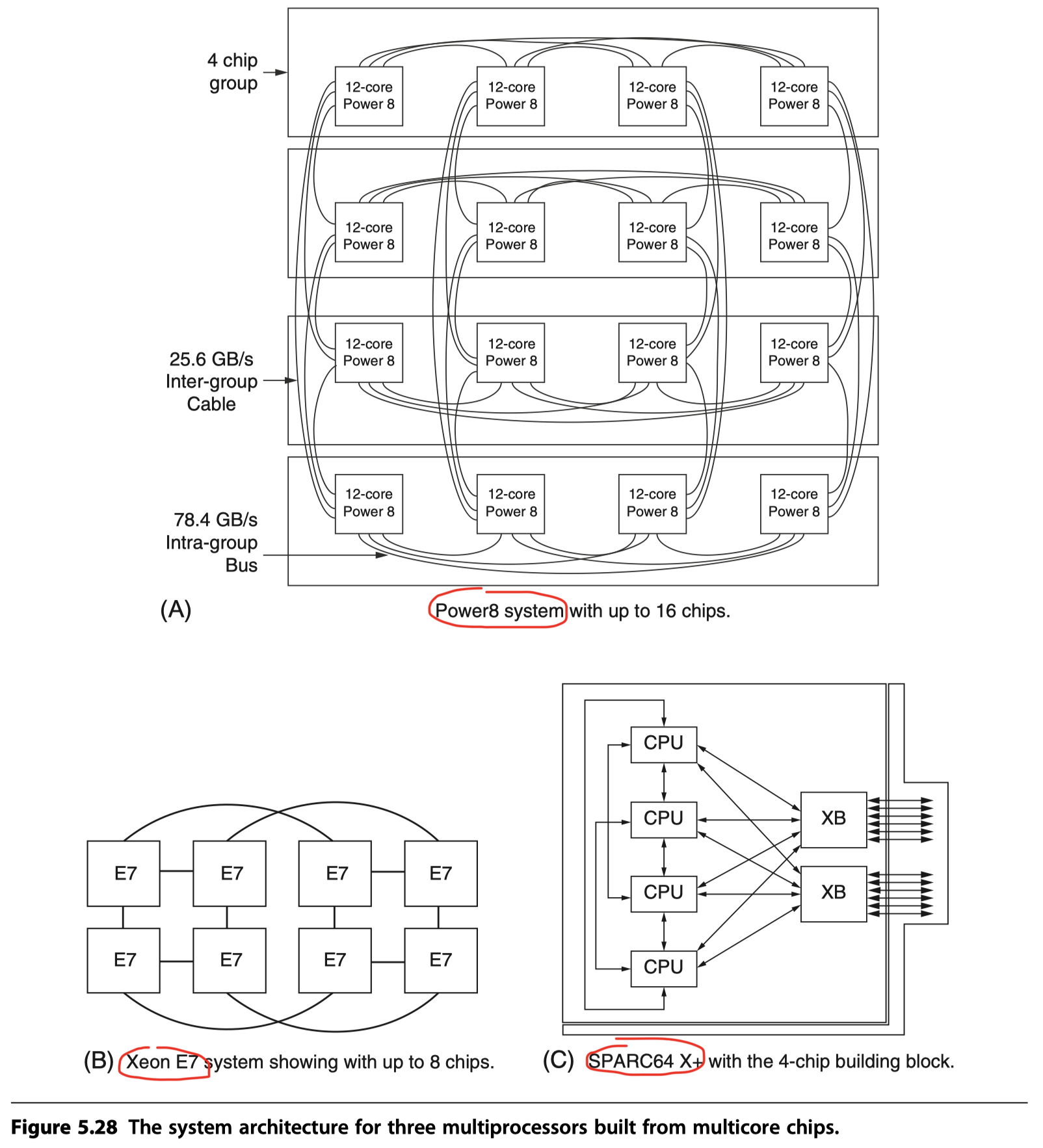
Performance of Multicore-Based Multiprocessors on a Multiprogrammed Workload
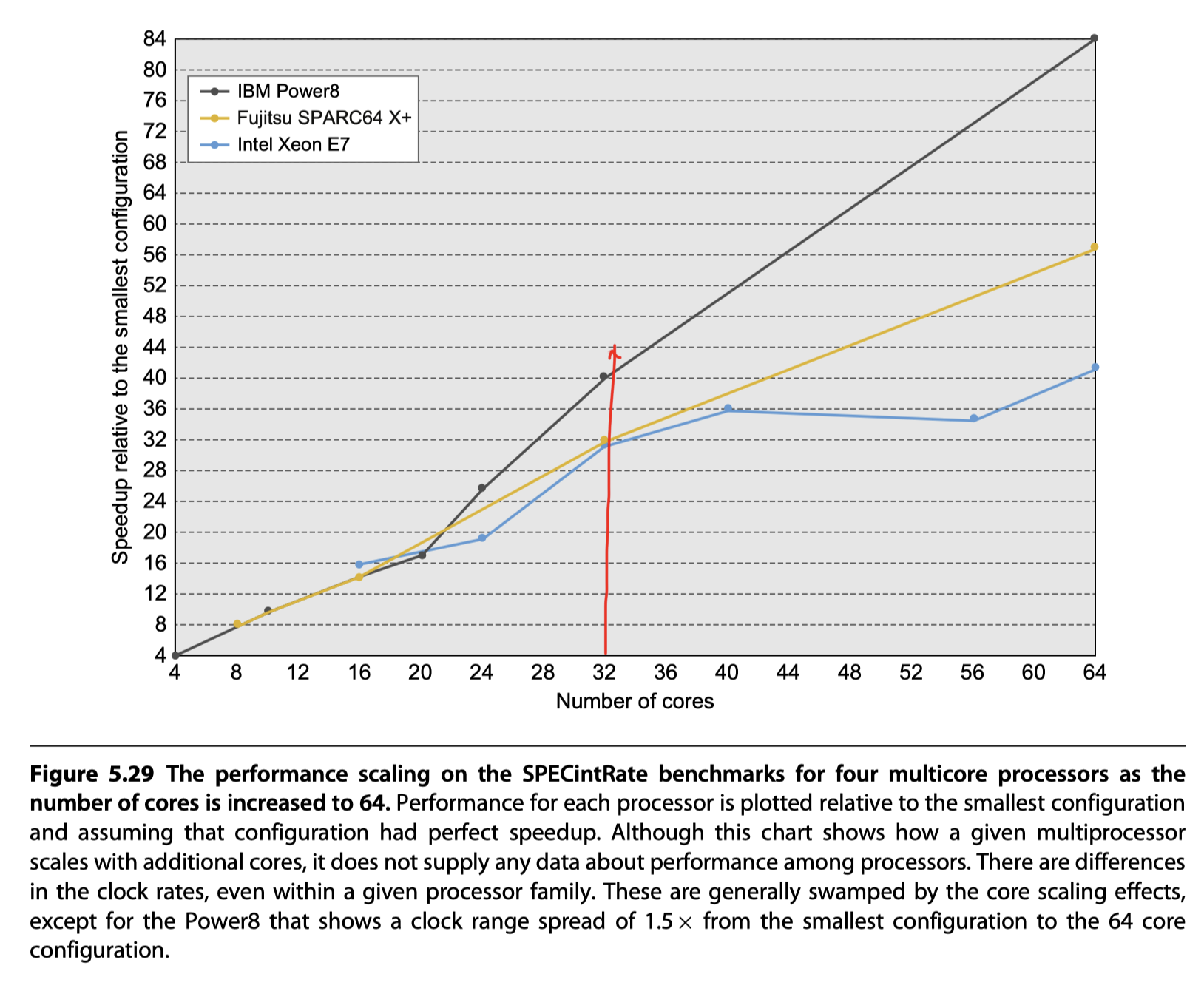
Scaling of SPECintRate result $\leq$ 64 cores (Figure 5.29)
- Xeon
- More core $\rightarrow$ Less L3 per core $\rightarrow$ More L3 miss $\rightarrow$ Band scalability
- IBM Power8
- Looks like have good scalability,
- But it’s due to the higher clock rate 4.4GHz of 64 core configuration than 3.0GHz of 4 core configuration
Scaling above 64 processors (Figure 5.30)
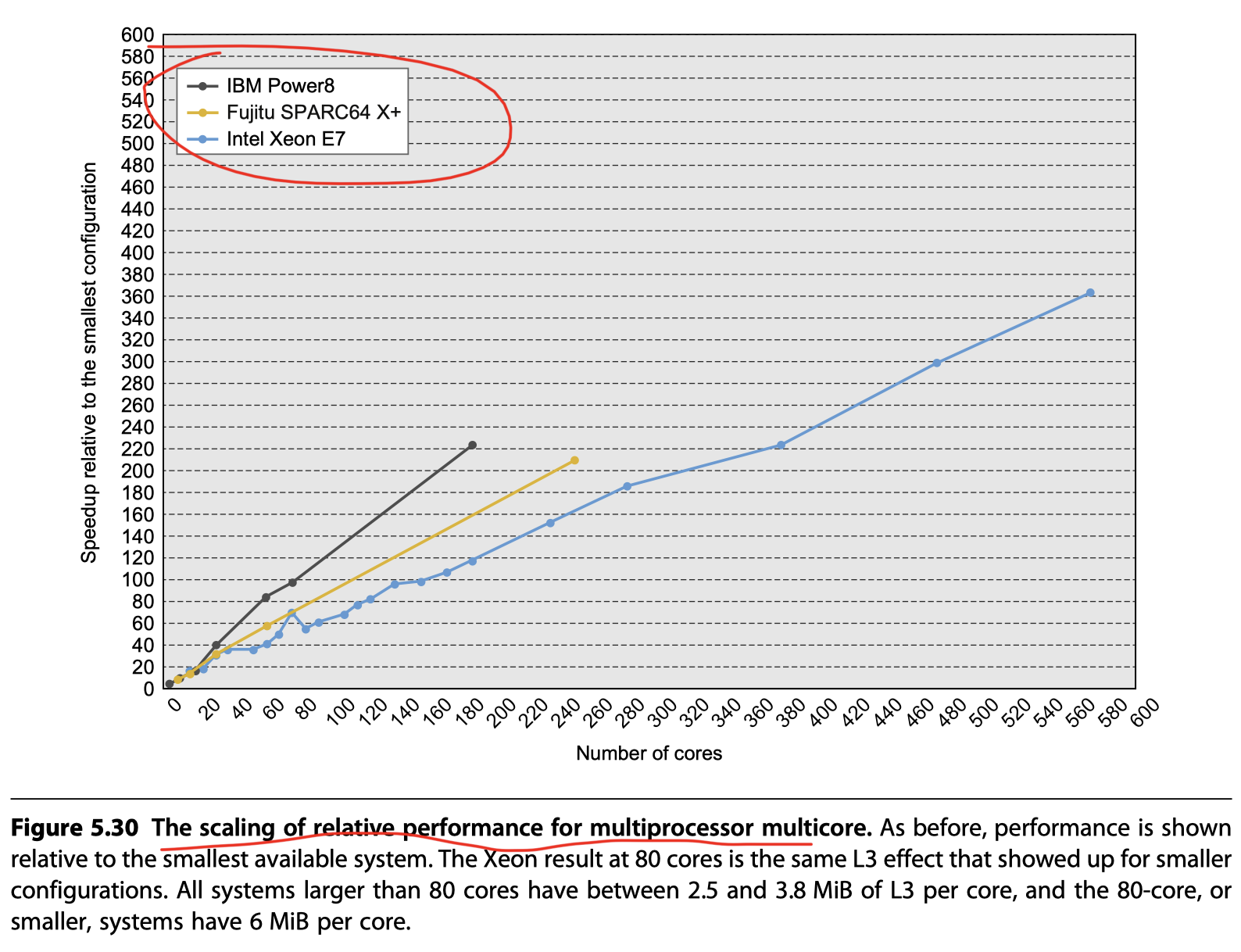
Scalability in an Xeon MP With Different Workloads
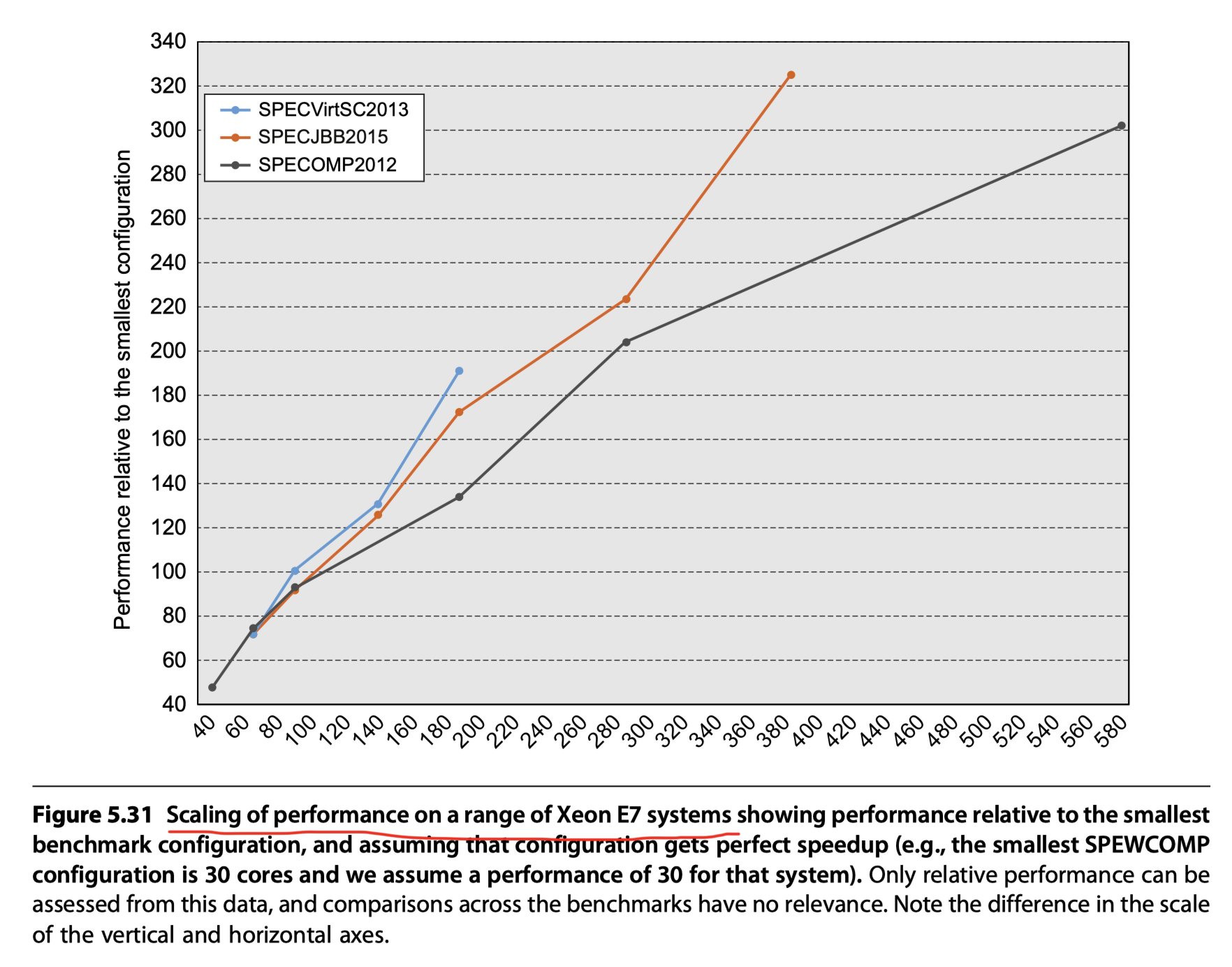
Three different workloads
- Java-based commercially oriented workload (SPECjbb2015)
- w/ Java VM software and the VM hypervisor
- Small proc-to-proc interaction
- 78~95% speedup efficiency
- Virtual machine workload (SPECVirt2013)
- w/ Java VM software and the VM hypervisor
- Small proc-to-proc interaction
- Almost linear speedup
- Scientific parallel processing workload (SPECOMP2012)
- True parallel code with multiple user processes sharing data and collaborating in the computation
- OpenMP standard for shared-memory parallel processing
- Fortran, C, C++
- Fluid dynamics, molecular modeling, image manipulation
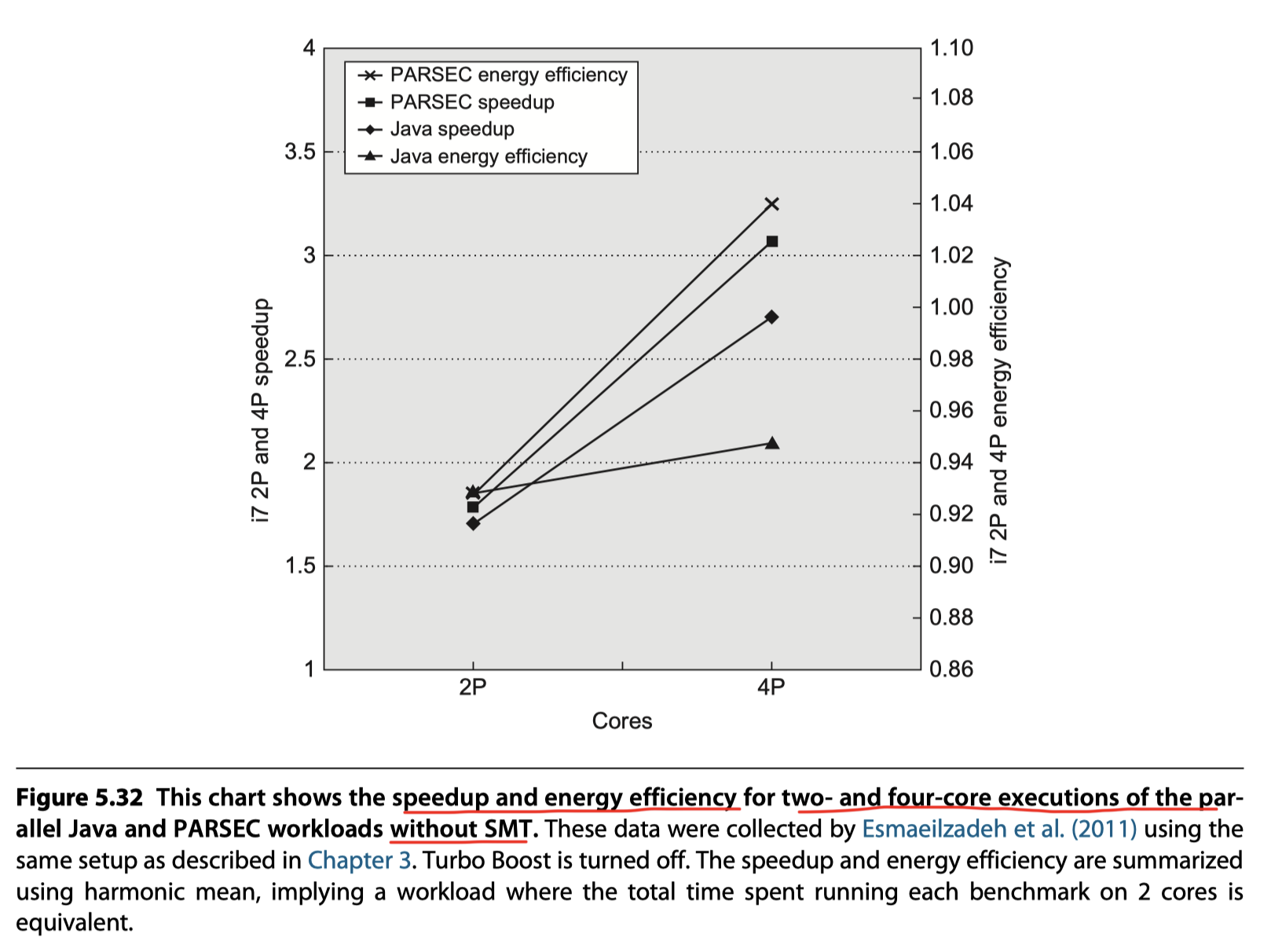
Performance and Energy Efficiency of the Intel i7 920 Multicore
Figure 5.32: Speedup and energy efficiency of the Java and PARSEC benchmarks without the use of SMT
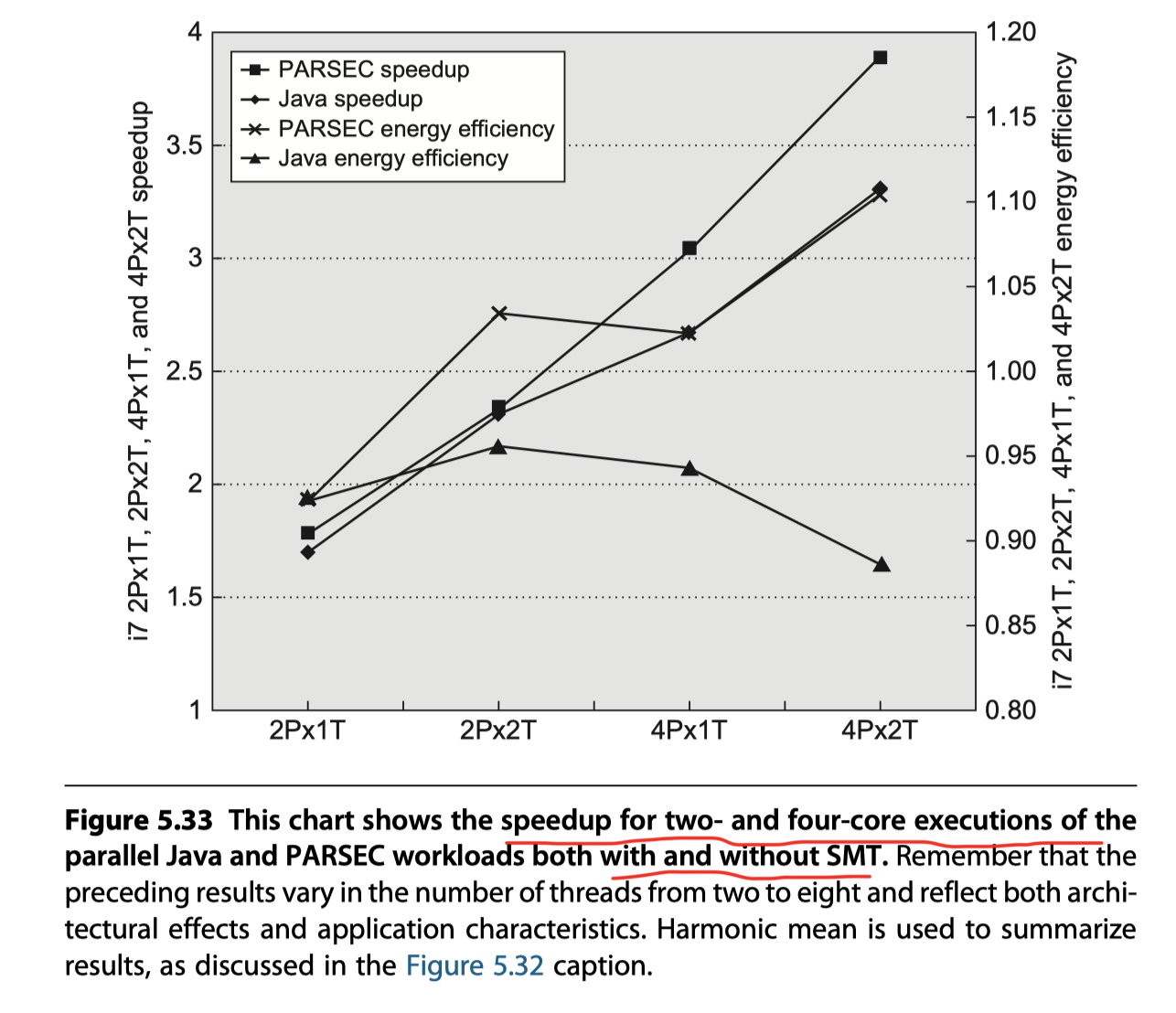
Putting Multicore and SMT Together
Figure 5.33: Speedup and energy efficiency of the Java and PARSEC benchmarks ==with and without the use of
- SMT can add to performance when there is sufficient thread-level parallelism available even in the multicore situation.
- Java’s bad scalability in energy efficiency $\rightarrow$ Amdahl’s law! (Due to serial parts in Java like garbage collectors for multi-threaded programs)
Reference
- Chapter 5 in Computer Architecture A Quantitative Approach (6th) by Hennessy and Patterson (2017)
- Notebook: Computer Architecture Quantitive Approach
- U.C.Berkeley lecture slide(CS252) on snooping vs directory based coherency by D. A. Patterson
- UMA and NUMA
- Apple M1 Chip
- Atomic Operation by Georgia Tech - Advanced Operating Systems
Notes Mentioning This Note
Table of Contents
- Multiprocessors and Thread-Level Parallelism
- Introduction
-
Centralized Shared-Memory Architectures
- What Is Multiprocessor Cache Coherence?
- Basic Schemes for Enforcing Coherence
- Snooping Coherence Protocols
- Basic Implementation Techniques
- An Example Protocol
- Extensions to the Basic Coherence Protocol
- Limitations in Symmetric Shared-Memory Multiprocessors and Snooping Protocols
- Implementing Snooping Cache Coherence
- Performance of Symmetric Shared-Memory Multiprocessors
- Distributed Shared-Memory and Directory-Based Coherence
- Synchronization: The Basics
- Models of Memory Consistency: An Introduction
- Cross-Cutting Issues
- Putting It All Together: Multicore Processors and Their Performance
- Reference