GPT3 Architecture
- What is GPT3 and its architecture? : Answer from ChatGPT, one of children of GPT3
- GPT-3 (Generative Pre-trained Transformer 3) is a language model developed by OpenAI, which is designed to generate human-like text based on its training data. It is one of the largest and most powerful language models created to date, with 175 billion parameters.
- GPT-3 uses a neural network architecture called a transformer, which enables it to process and understand language in a way that is similar to how humans do. This allows it to perform a variety of natural language processing (NLP) tasks, such as language translation, text summarization, and question-answering, among others.
- GPT-3 has received a lot of attention due to its ability to generate highly convincing and coherent text, which has many potential applications in areas such as content creation, chatbots, and virtual assistants. However, it has also raised concerns about the potential misuse of such powerful language models, particularly in the areas of fake news and propaganda.
- GPT as a Children of the Transformer?
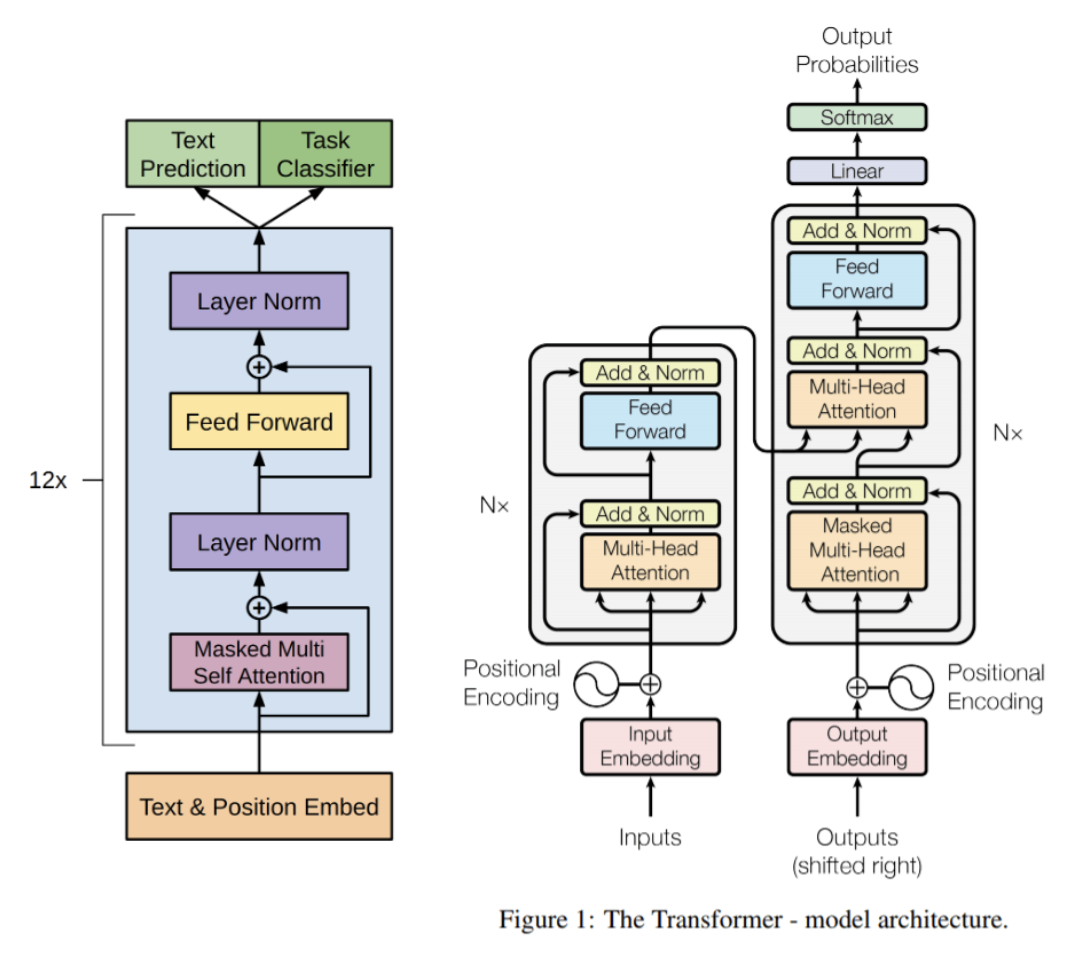
- Basically, hugely augmented decoder stack of transformer introduced in Attention is All You Need
- In GPT, like traditional language models, outputs one token at a time.
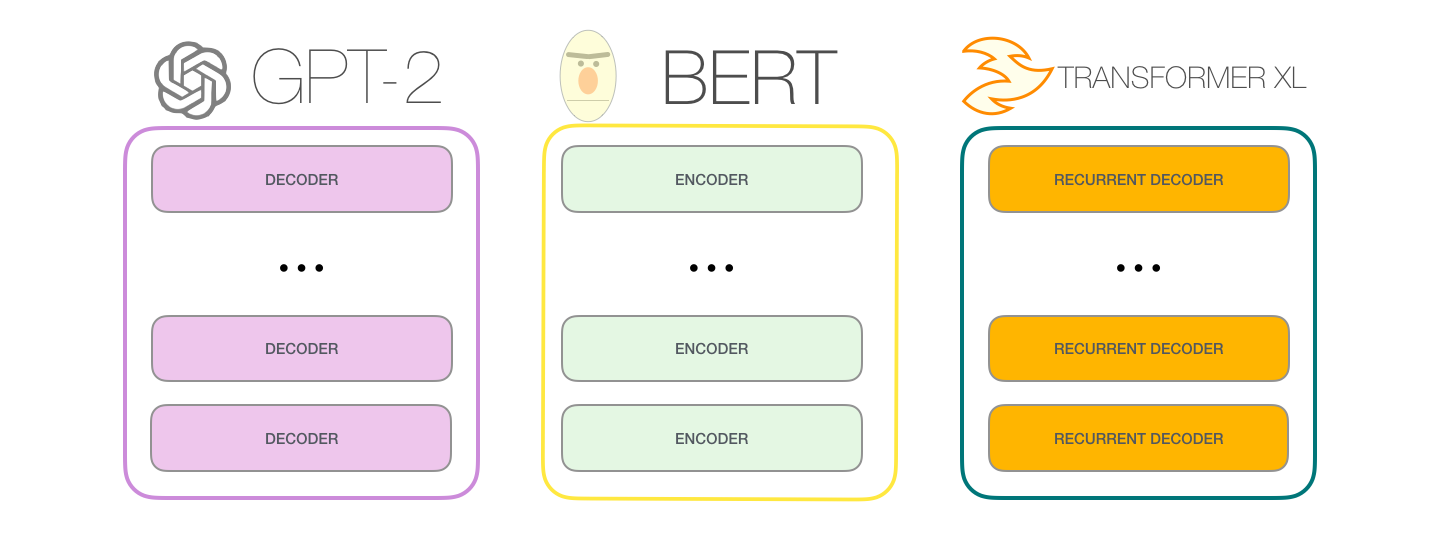

High Level Description of GPT3
- GPT2 = A stack of 12 decoders with 12 attention heads
- GPT3 = A stack of 96 decoders with 96 attention heads
Input/Output
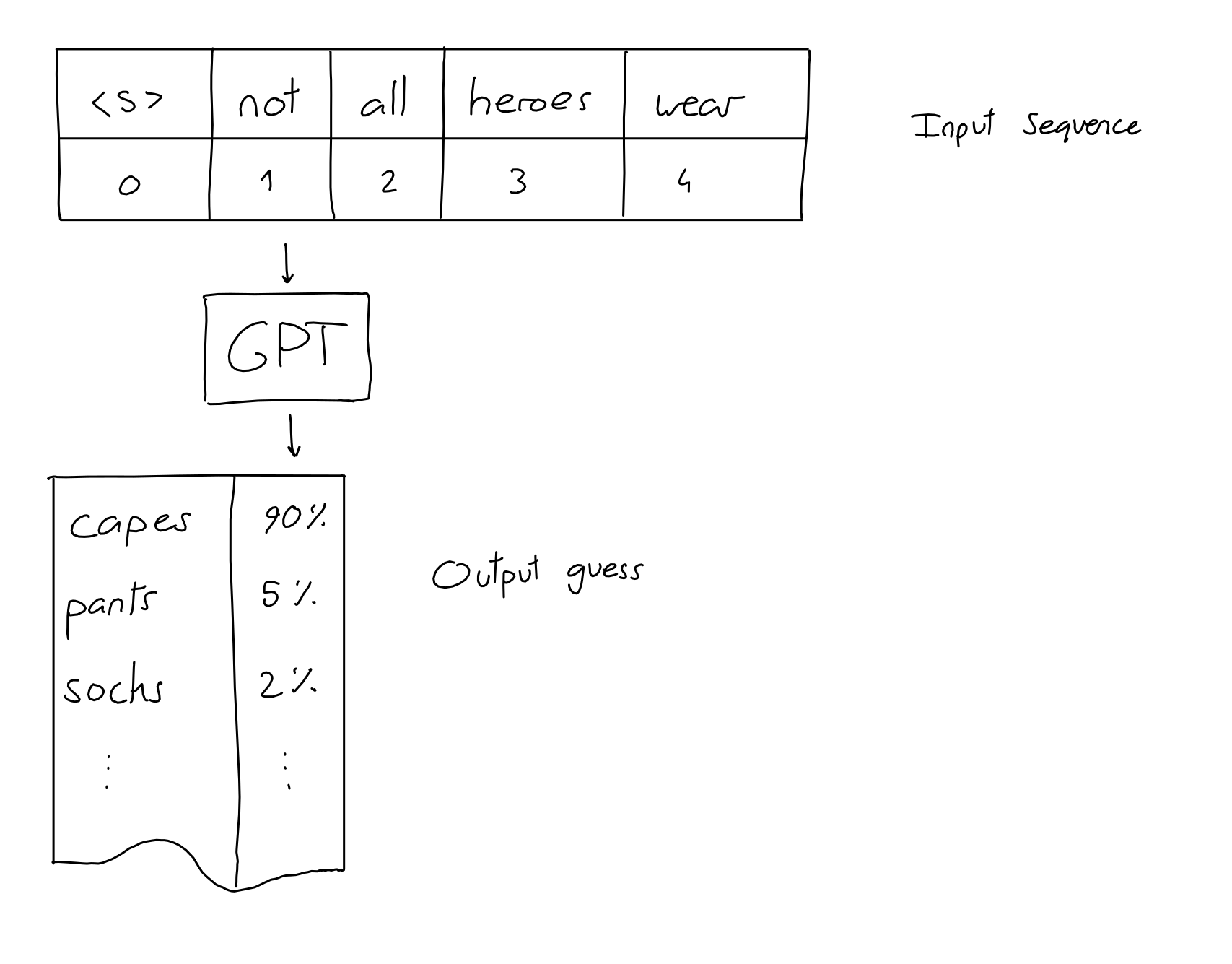
- Input : A sequence of N words (a.k.a tokens).
- 2048 words for GPT-3
- One input word at one time
- Output: A guess for the word most likely to be put at the end of the input sequence.

- For GPT-3, output is not just a single guess, it’s a sequence (length 2048) of guesses (a probability for each likely word)
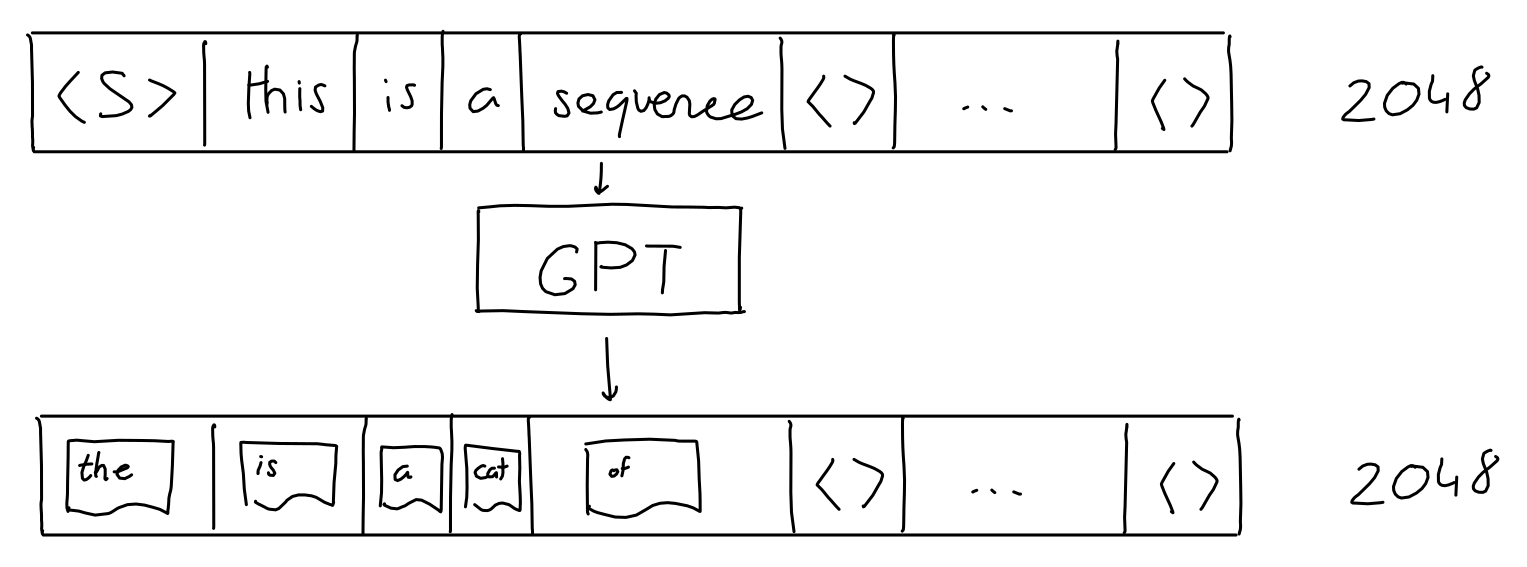
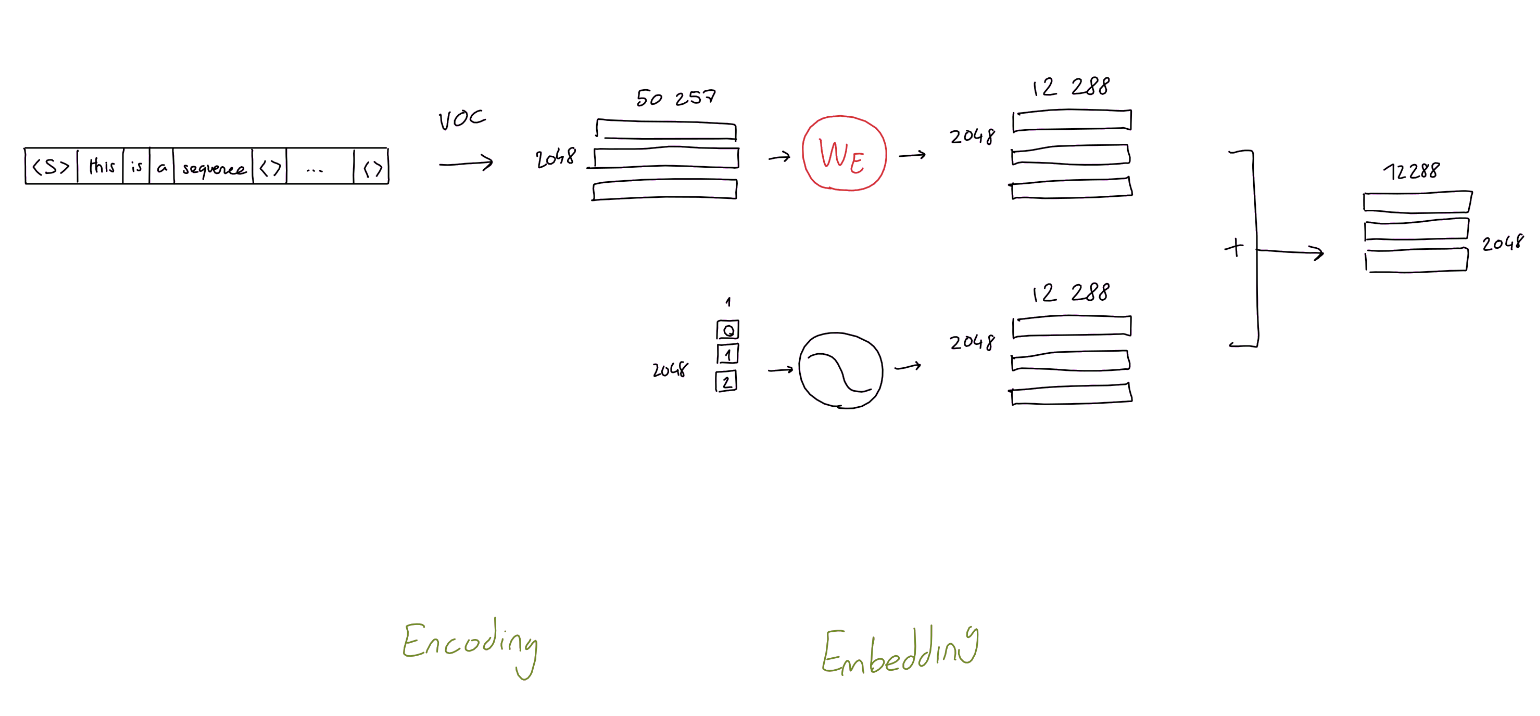
Encoding of Word Sequence
- GPT3 as a ML algorithm, it operates on vectors of numbers
- How to convert words into vectors?
- GPT3’s vocabulary = 50257 words
- One-hot encoding: One word = 50257-dim vector with only one element is one and all zero for the other elements

- 2048 words $\rightarrow$ Matrix with 2048x50257 Binary matrix
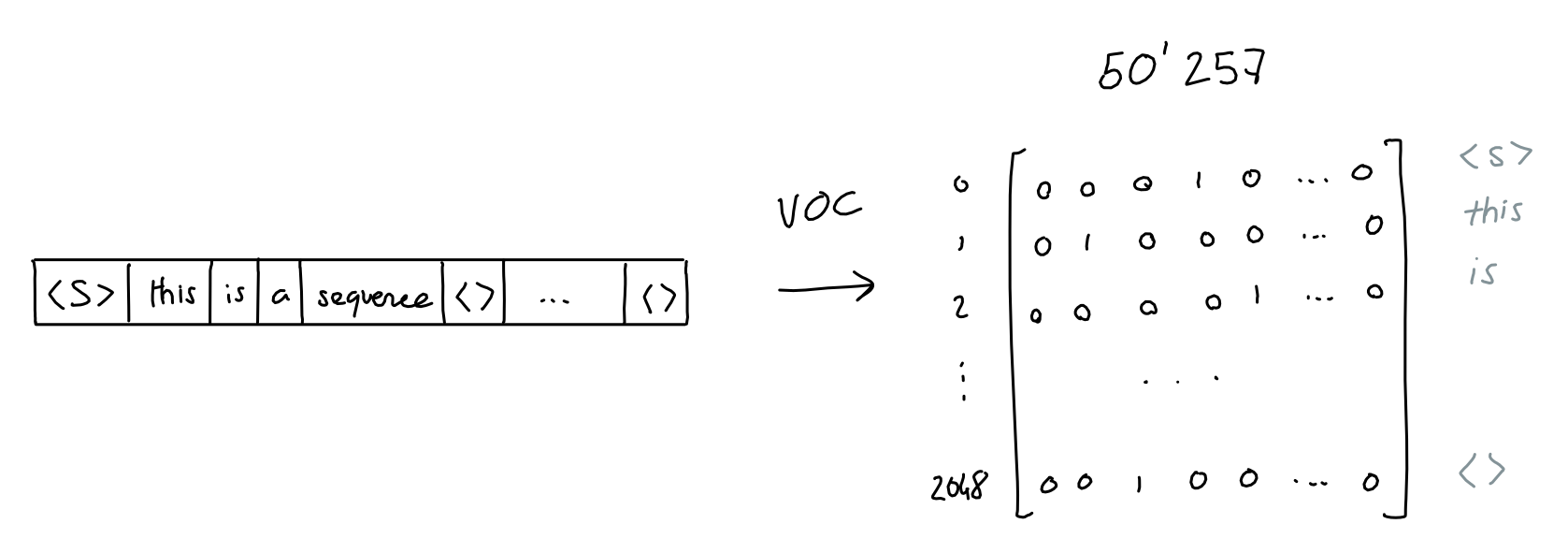
- GPT-3 uses byte-level Byte Pair Encoding (BPE) tokenization for efficiency
- Word as token $\rightarrow$ Groups of characters (sub-words of a word) as token
- Check OpenAI’s tokenizer tool
Embedding of Encoded Word Sequence
- 50257 dim-vector is too big!
- Let’s Make it short!
- Need to learn an embedding function
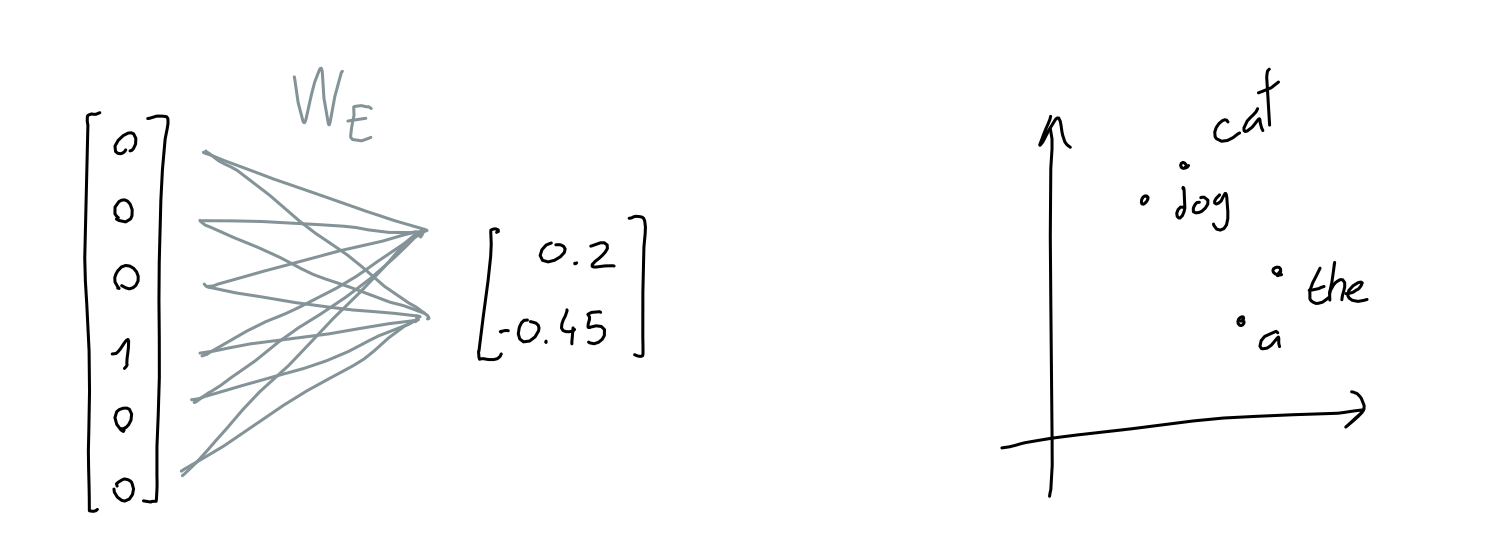
- GPT uses 12288 dimensions as its embedding dimension!
- How to embed?
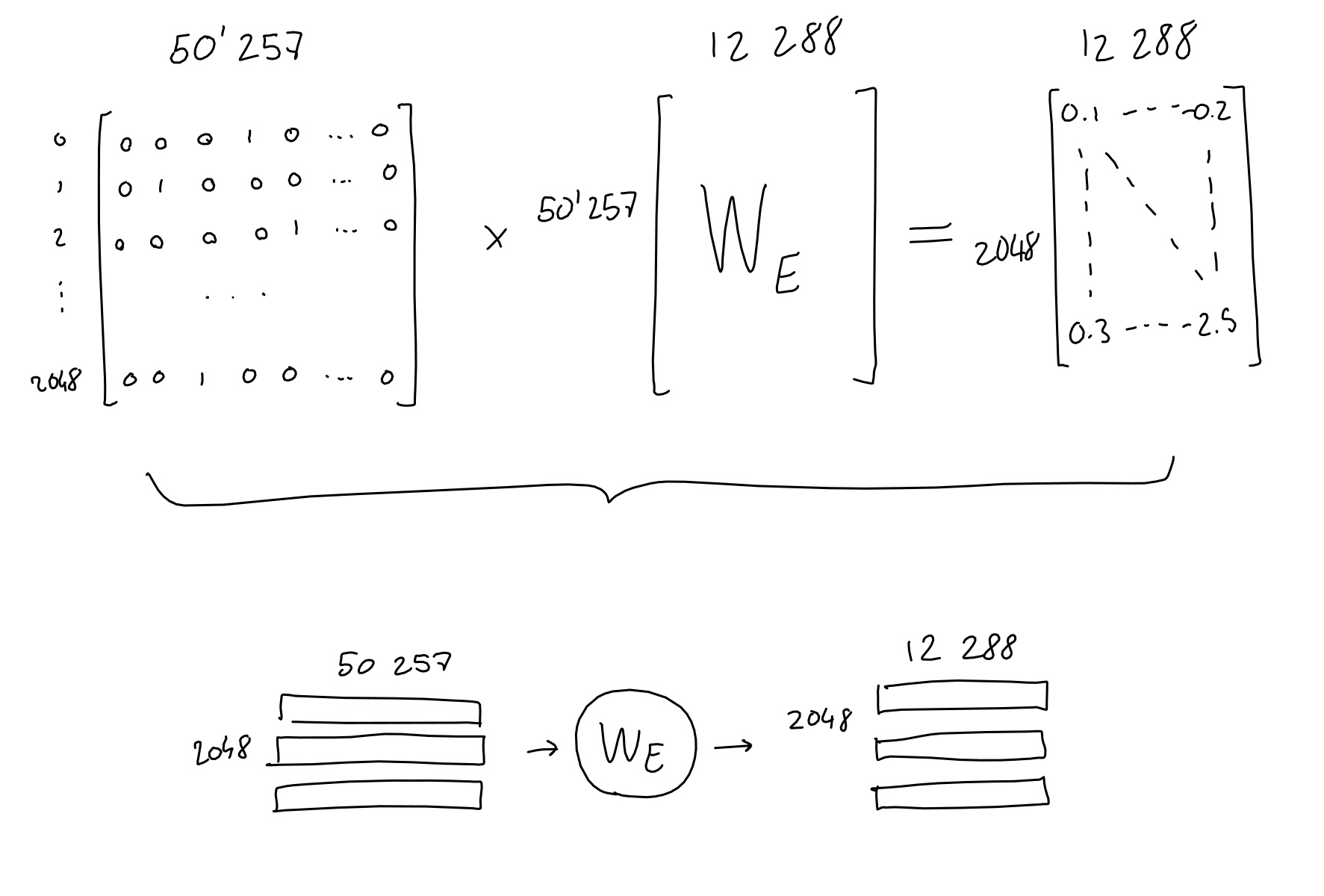
- 2048 word-sequence in a vocabulary with 50257 words
- $\rightarrow$ 2048x50257 Sequence-encoding matrix $A_E$
- $\rightarrow$ Multiply with 50257x12288 Embedding-weights matrix : Learned parameters! $A_E\times W_E$
- $\rightarrow$ 2048x12288 Sequence-embedding matrix
- About the matrix multiplication $A_E\times W_E = X_{TokenEmbedding}$
- Not actually multiplication
- Just simple table lookup
- Steps:
- Get index $j$ of the non-zero element of the $i$-th row of Encoding matrix $A_E$
- Find and fetch $j$-th row of Weight matrix $W_E$
- Put it in $i$-th row of Embedding matrix $X_{TokenEmbedding}$
- Q: What if embeddings are distributed across the system?
- Q: When is the 50257x12288 Embedding-weights matrix trained? Is it pretrained?
Positional Encoding
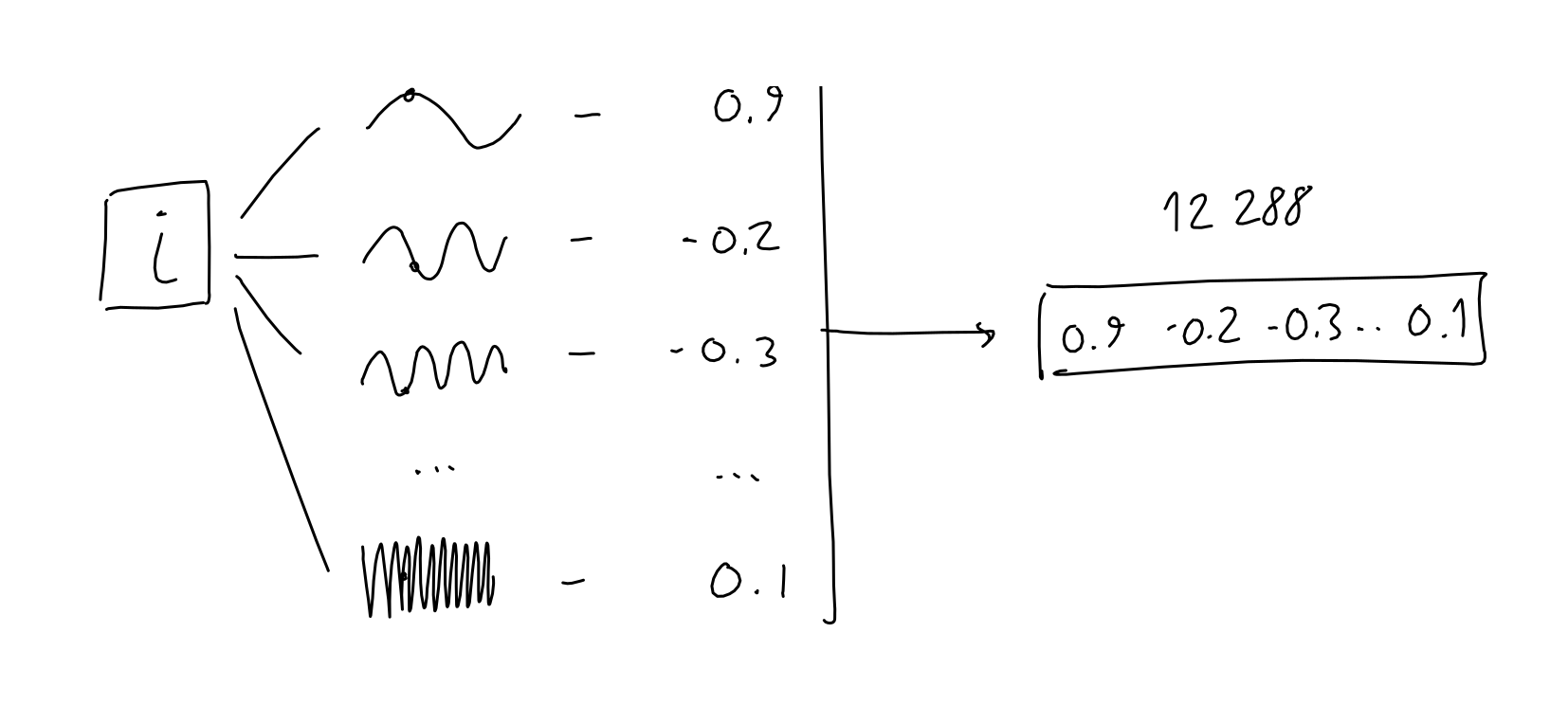
- 2048 word’s position $\rightarrow$ 12288 sinusoidal functions, each with a different frequency
- Since #sine-frequency > #words, each position will give unique position vector with relative positional information, just like Fourier transformation does.
- So, this vector can represent
- Unique position of each word
- Periodically relative relations among words
- Now, we have positional encoding matrix $X_{PositionalEncoding}$ with (2048 $\times$ 12288) size
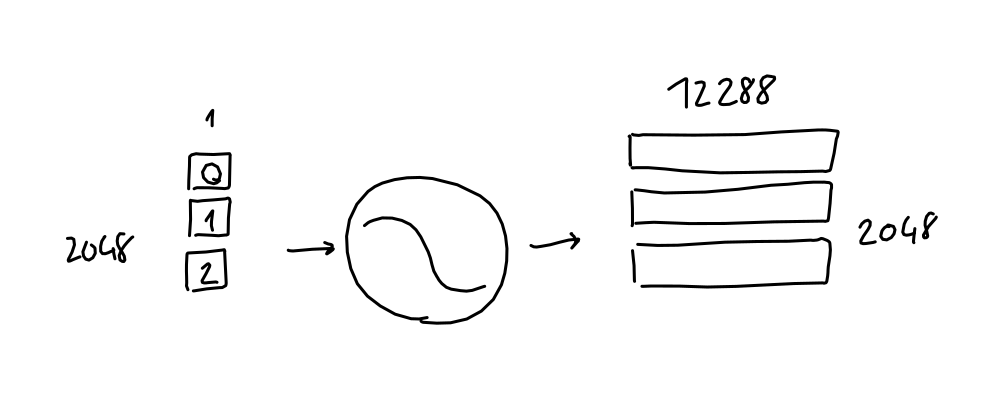
Final Embedding Matrix
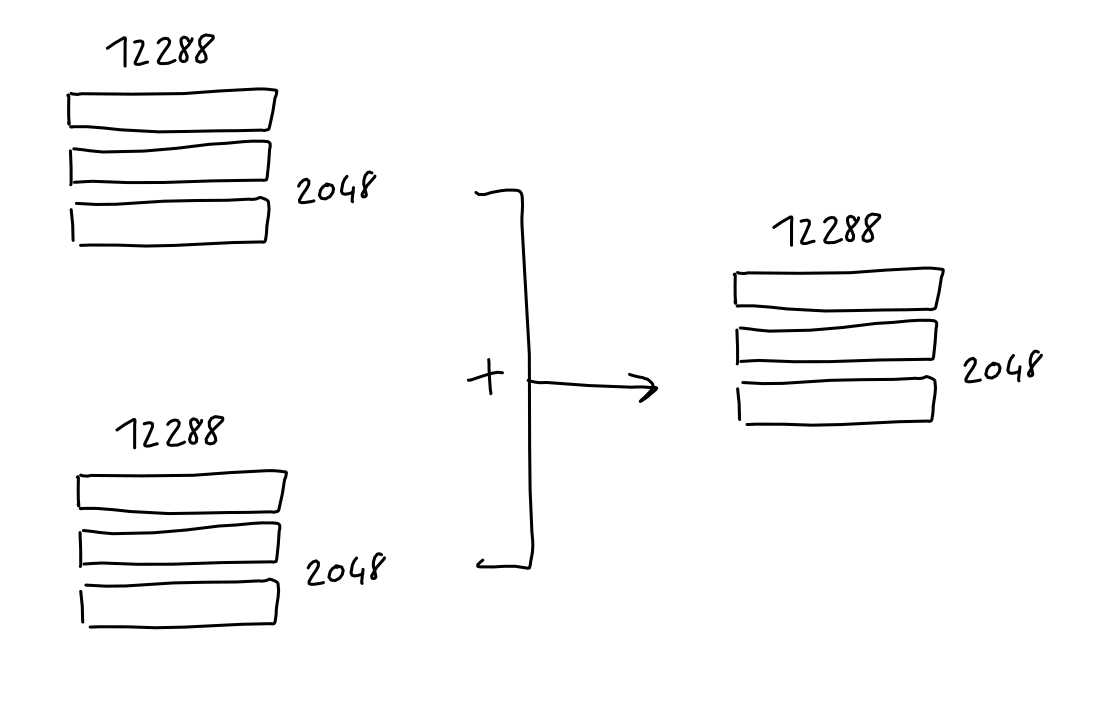
-
Final embedding matrix (2048x12288) $X$
- = Sequence-Embedding matrix (2048x12288) $X_{TokenEmbedding}$
-
- Positional-Encoding matrix (2048x12288) $X_{PositionalEncoding}$
Attention (Simplified)
- What is attention?
- An operation that gives …
- Prediction which input tokens to focus on and how much important it is
- for each output in the sequence
- Attention toy model
- Sequence of 3 tokens (2048 in GPT3) with 512-dimensional embedding (12288 in GPT3)
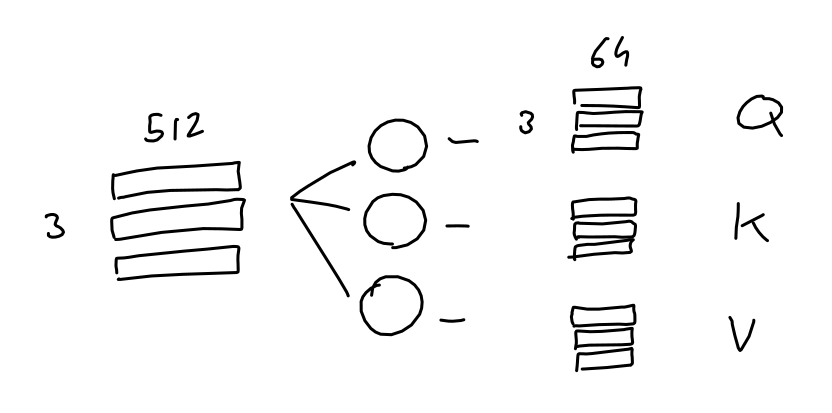
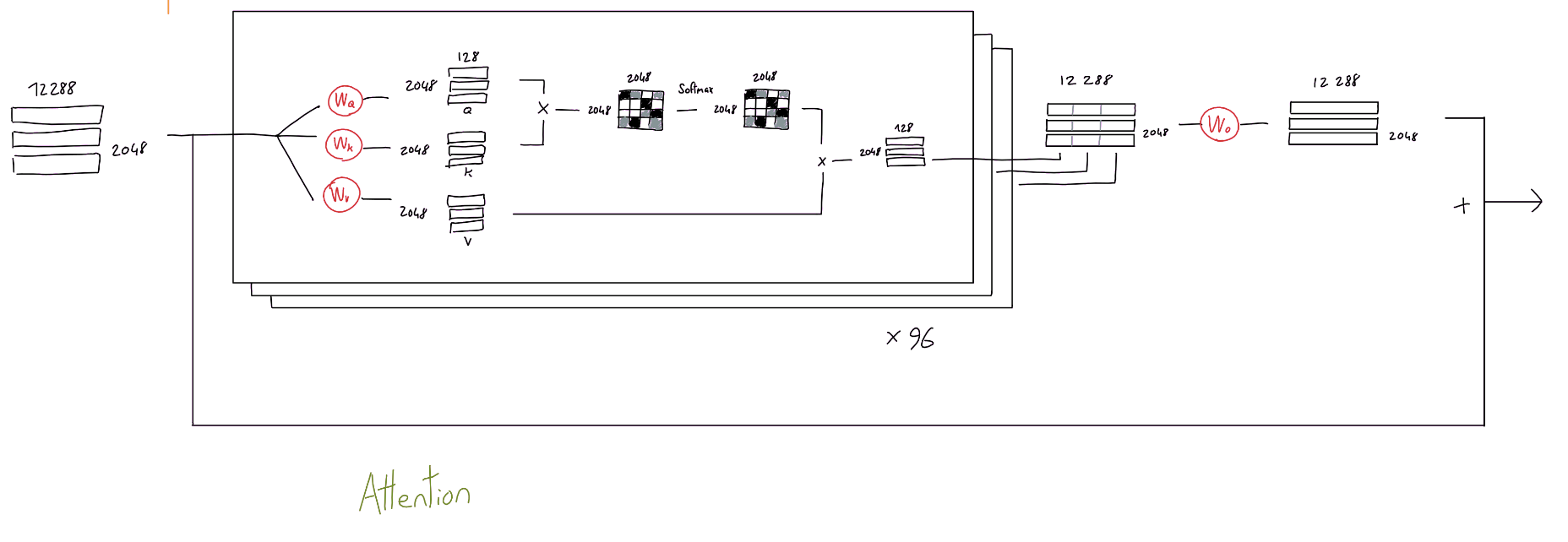
- Step1: Make $Q$, $K$, $V$ using 3 linear projection matrices $W_q, W_k, W_v$
- Learn 3 linear projections $W_q, W_k, W_v$
- 512(Embedding dimension, 12288 in GPT3) x64($QKV$’s columns, 124 in GPT3)
- Apply them to the sequence embeddings
- Generate 3 different matrices $Q$, $K$, and $V$
- $Q$: Queries = $X\times W_q$
- $K$: Keys = $X\times W_q$
- $V$: Values = $X\times W_q$
- Learn 3 linear projections $W_q, W_k, W_v$
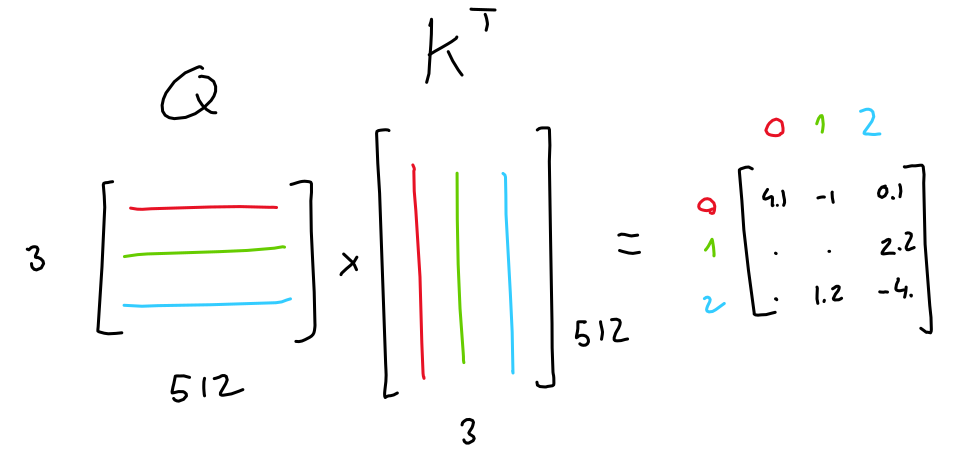
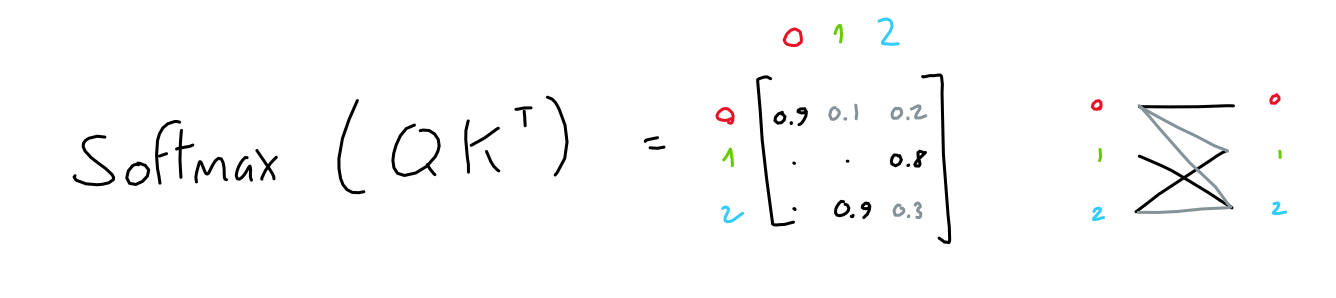
- Step2: Importance matrix
- Multiply queries and keys
- $Q_{(3\times 64)}\times K^T_{(64\times 3)}$
- In GPT3: $Q_{(2048\times 128)}\times K^T_{(128\times 2048)}$
- Apply softmax function to the 3x3 matrix result
- $Softmax~(Q_{(3\times 64)}\times K^T_{(64\times 3)})_{(3\times 3)}$
- Meaning?
- Only interaction between different tokens
- Which tells the importance of each token to each other tokens
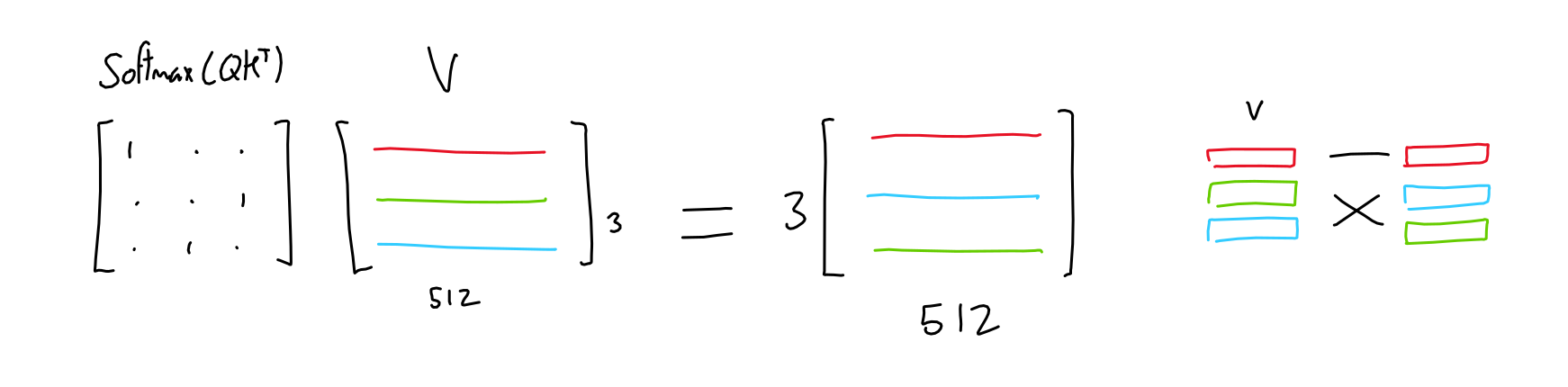
- Step3: Make weighted values $Y$
- Multiply the importance matrix to the values
- $Y=$ $Softmax$$(Q_{(3\times 64)}\times K^T_{(64\times 3)}$$){(3\times 3)}$$\times$$V{(3\times 64)}$
- Computation Steps: Save the previous Q and K history !!
- The i-th row vector $x_i$ of $X$ matrix with 12288 dimension is fed as input
- The $Q(x_i)$, $K(x_i)$, $V(x_i)$ are calculated and used to make output vector $x_{i+1}$
- Then, you feed $x_{i+1}$ to the decoder stack for next output $x_{i+2}$.
- The role of $V(x_i)$ is completed, so remove $V(x_i)$
- Due to masked self-attention, all the previous $Q_{x_{j} ~where ~j\le i+1}$ and $K_{x_{j} ~where ~j\le i+1}$ including $Q(x_i)$, $K(x_i)$ are reused for next decoding steps
- So, all the previous $Q_{x_{j} ~where ~j\le i+1}$ and $K_{x_{j} ~where ~j\le i+1}$ vectors should be stored in the memory until the end of sentence generation!!
Multi-Head Attention
- GPT-3 used 96 multi-head attention with different $W_q, W_k, W_v$ projection weights
- So, 96x3x(Embedding-dim)x($QKV$’s columns) parameters from linear projections
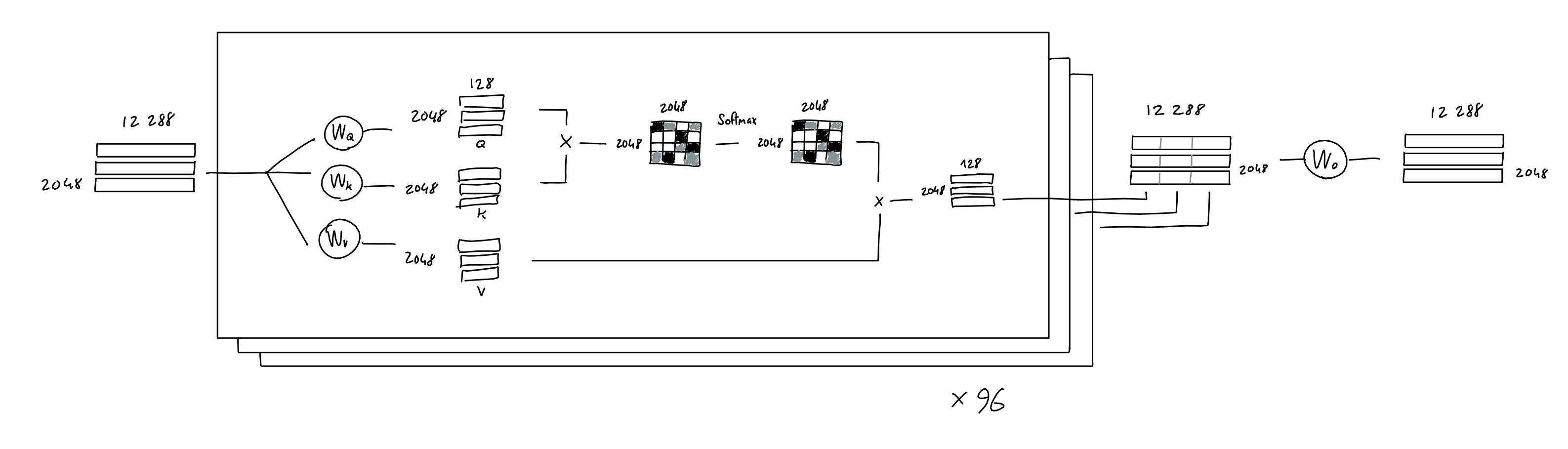
- Use results of multi-head attention $Y$s as input again!
- $Y$ = 2048 (Tokens) $\times$ 128 ($QKV$’s columns)
- Concatenate 96 $Y$s = 12288 = 96 $\times$ 2048 $\times$ 128
- So, now you have 2048 (Tokens) $\times$ 12288 (Embedding-dim)
- GPT-3 uses sparse attention ?
- $QKV$ calculation using big weight matrix and split ?
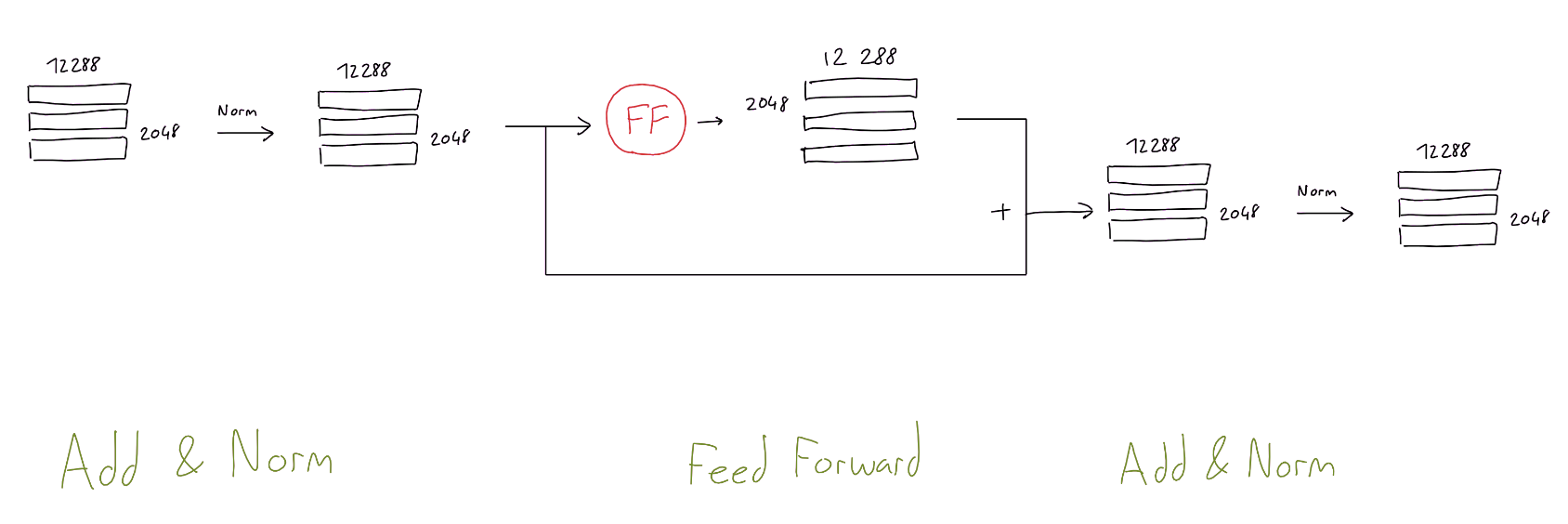
Feed Forward
- 1 Hidden layer
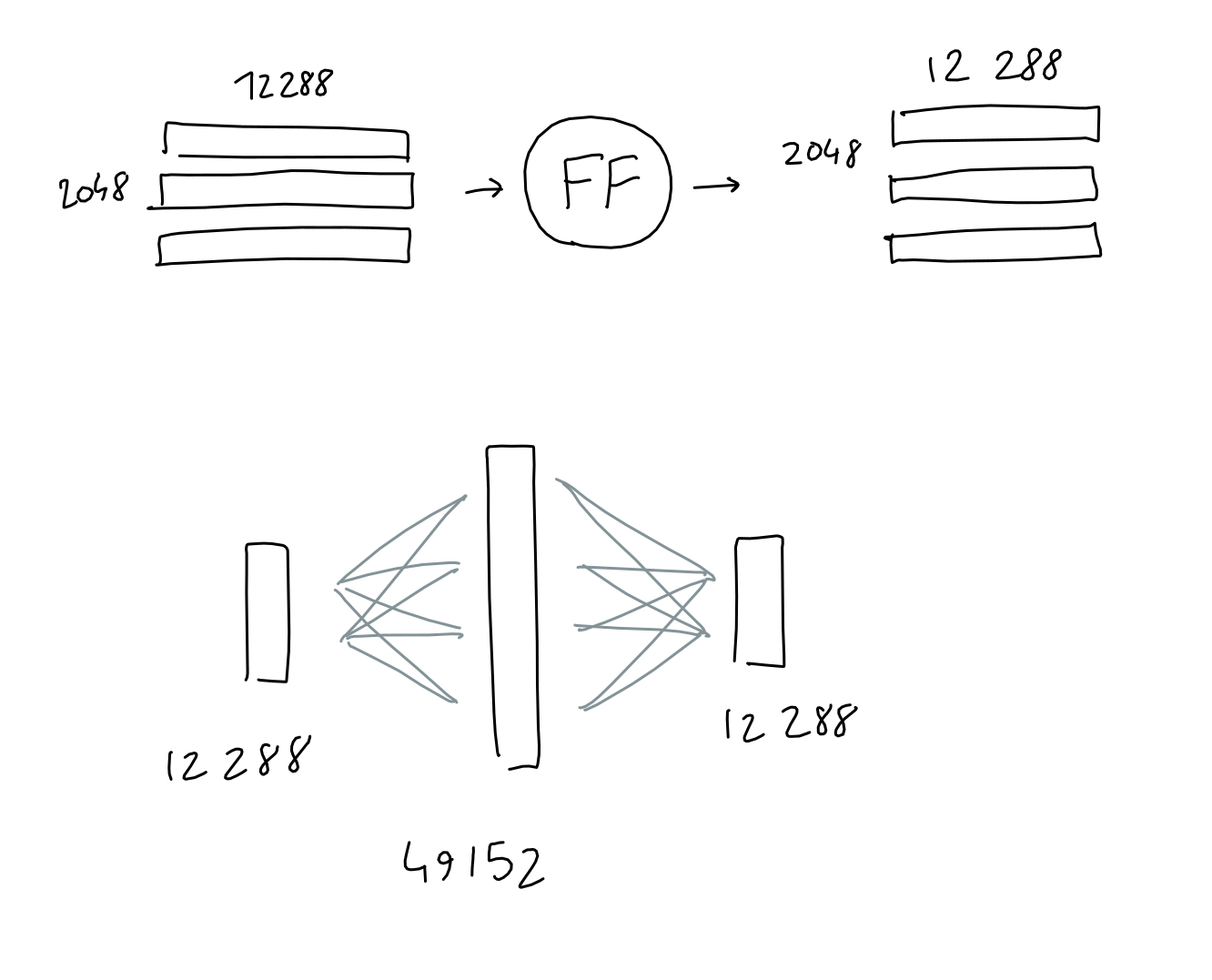
- Input and output = (2048 $\times$ 12288) with 12288 input/output neurons
- Hidden layer = 49152 hidden neurons = (4 $\times$ 12288)
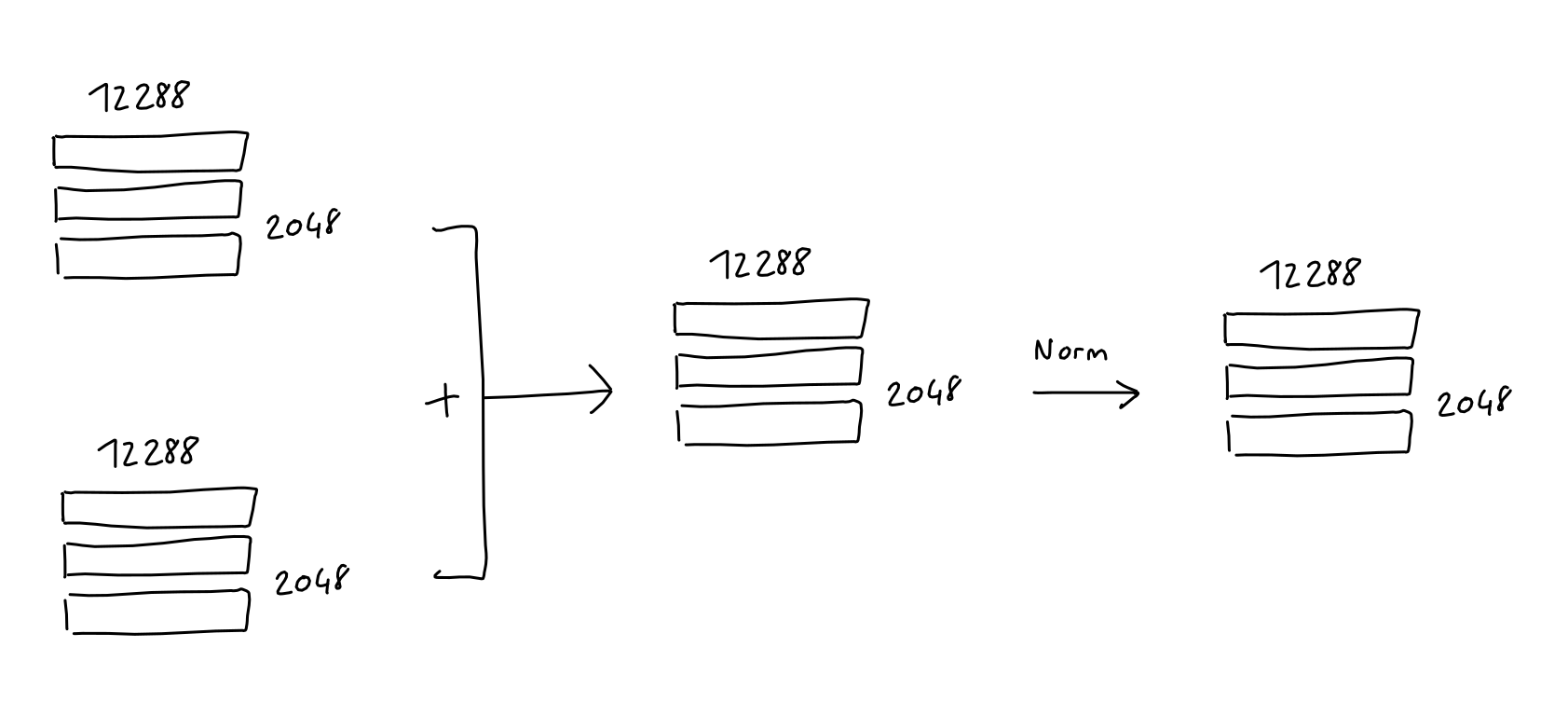
Add & Norm
- After Multi-Head attention and the Feed Forward blocks
- Input + Output $\rightarrow$ Normalize (like ResNet)
- “Layer normalization was moved to the input of each sub-block, similar to a pre-activation residual network and an additional layer normalization was added after the final self-attention block”?
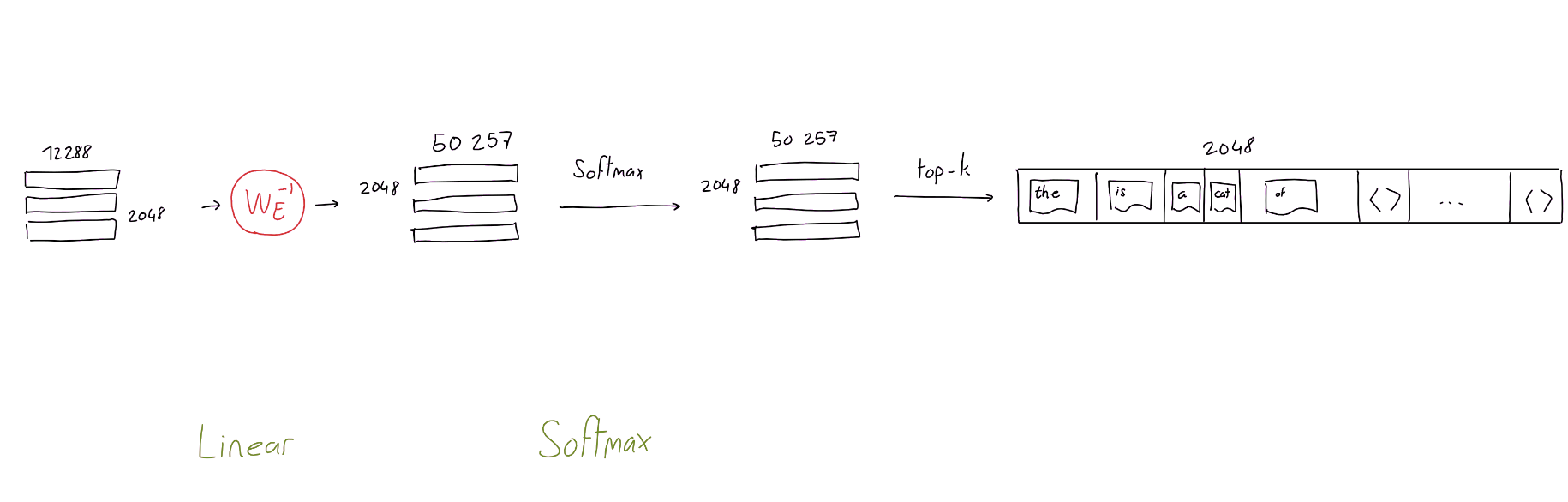
Decoding
- The output from the multi-head attention layer $\rightarrow$ Input for decoding
- Decoding is to invert
- the 12288-dim embedding vector back
- to the word vector with 50257-dim (i.e vocabulary size)
- filled with likelihood of each word in the vocabulary
- Given probability matrix, $top-k$ will synthesize the final sentence output!
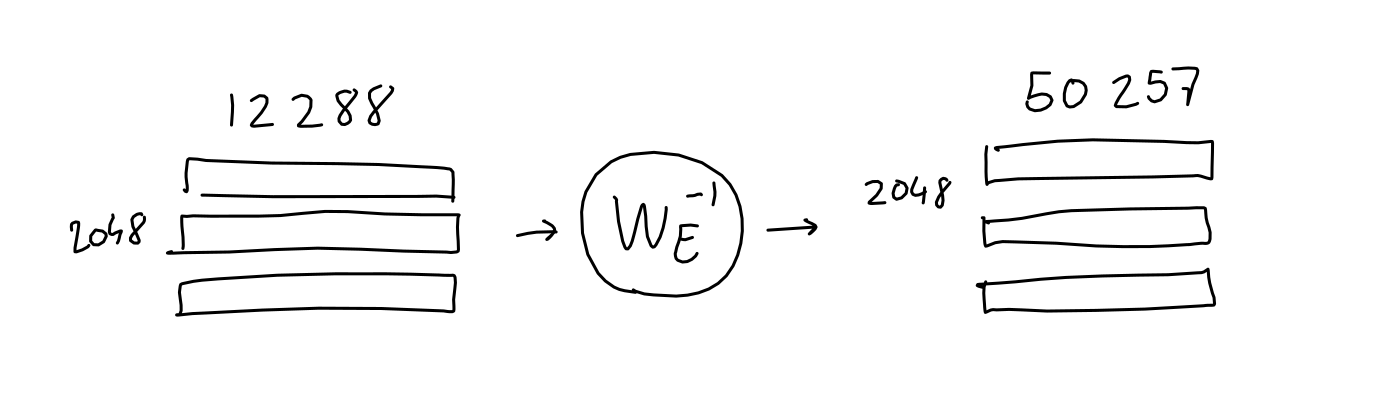

Full Architecture
- 96 Multi-heads
- Decoding
- Full architecture in one picture

Application: Summarization of An Article
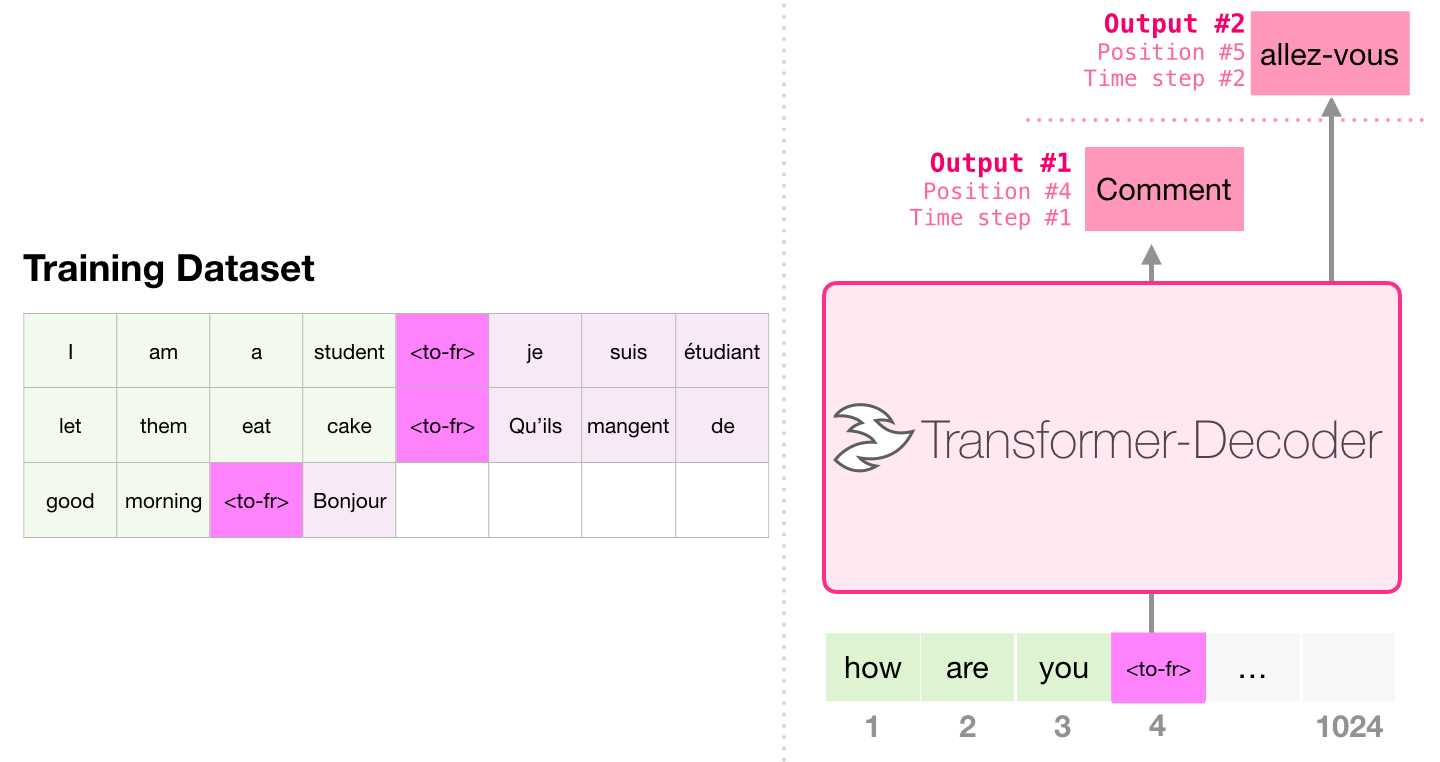
Machine translation
- From English to French
Summarization
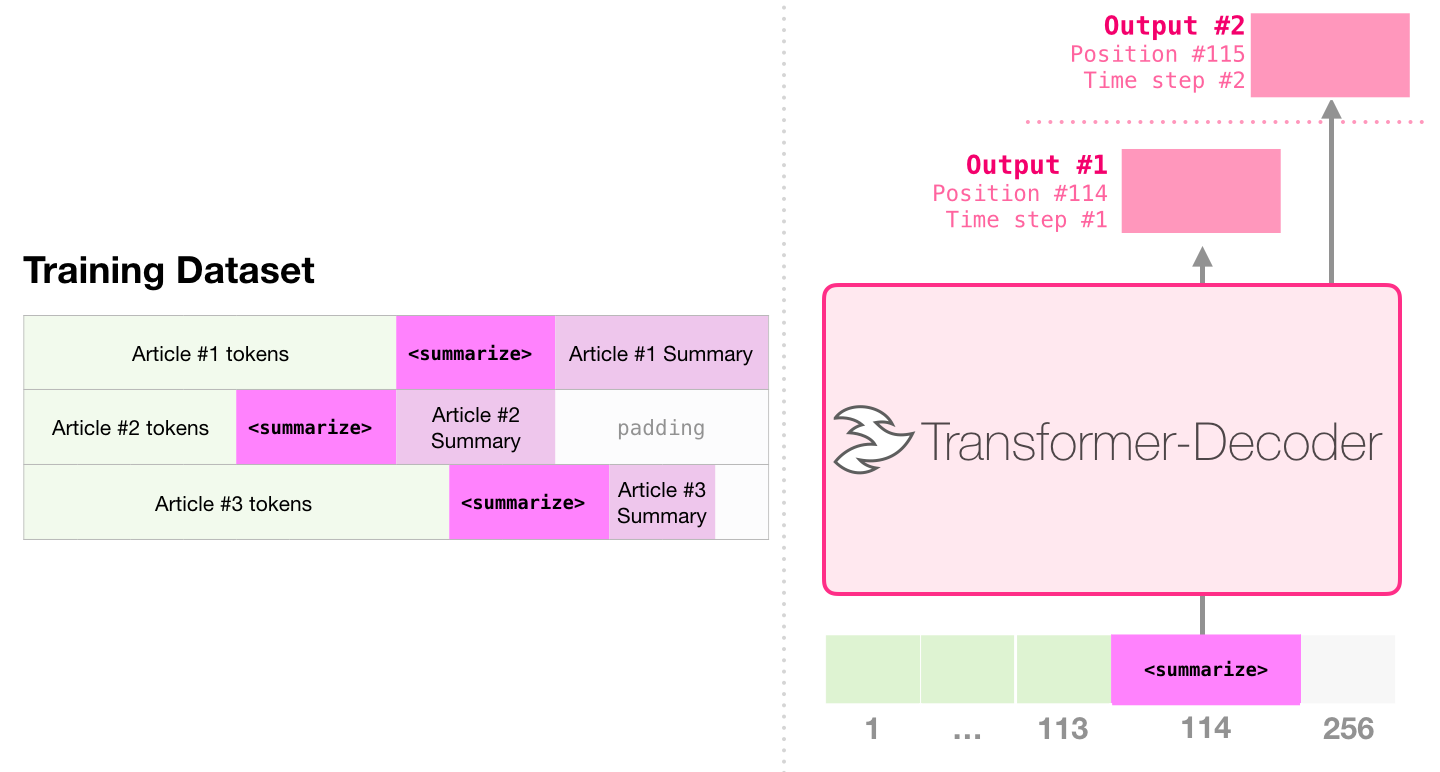
- If you train the wikipedia pages (with summaries and articles in it) to GPT,
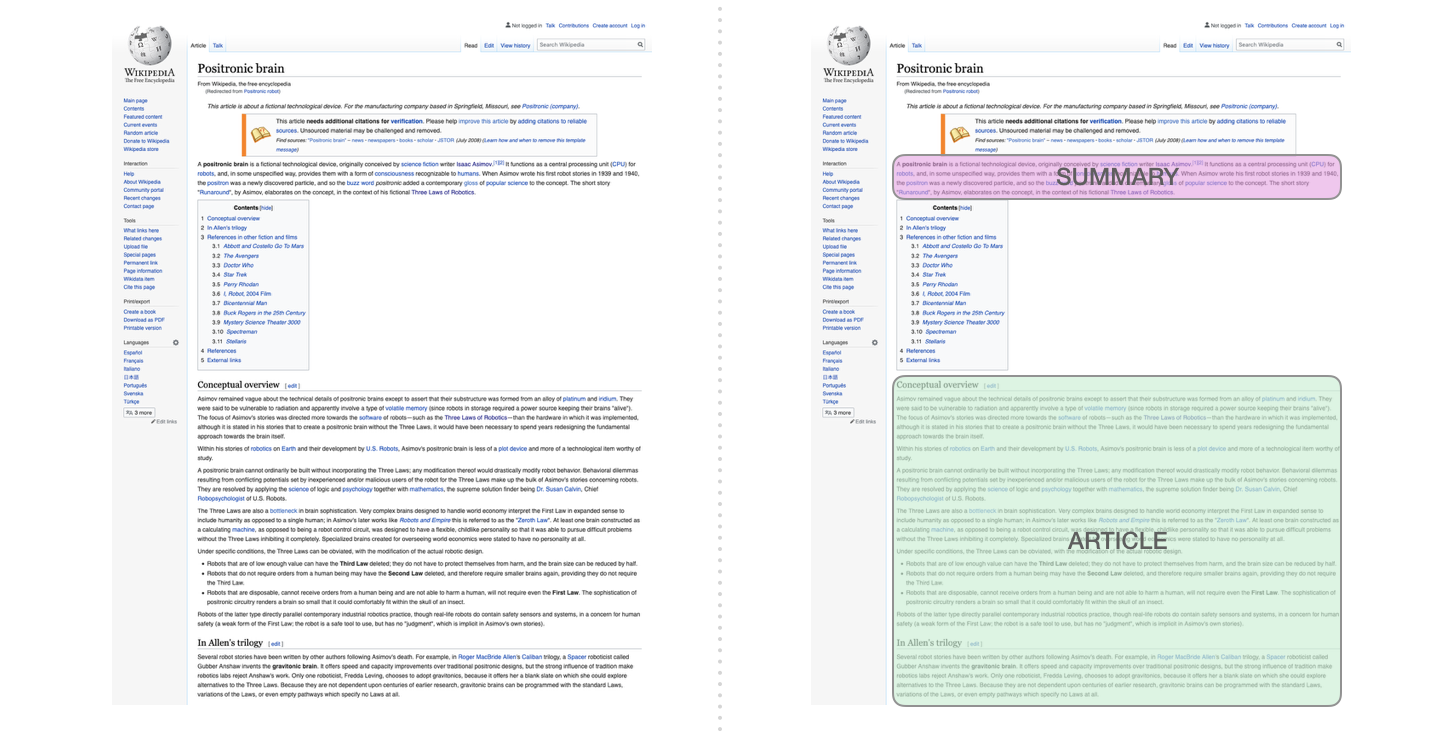
- The model can generate “summary of a given article”!
Reference:
- The GPT-3 Architecture, on a Napkin
- The Illustrated GPT-2 (Visualizing Transformer Language Models)
- Attention is All You Need
- [[ Efficient Estimation of Word Representations in Vector Space ]]
Notes Mentioning This Note
Table of Contents
- GPT3 Architecture
- High Level Description of GPT3
- Input/Output
- Encoding of Word Sequence
- Embedding of Encoded Word Sequence
- Positional Encoding
- Final Embedding Matrix
- Attention (Simplified)
- Multi-Head Attention
- Feed Forward
- Add & Norm
- Decoding
- Full Architecture
- Application: Summarization of An Article
- Reference: